Every agentic system that actually ships ends up needing three delegation patterns: one that blocks, one that fires and forgets, and one that runs later. The question isn't whether you need sub-agents — it's how you wire them up.
Sub-agents unlock a few key things that matter in agentic systems: context compression, parallel execution, and async delegation. A parent agent that can hand off work to isolated sub-agents stays lean across long conversations, runs independent tasks simultaneously, and delegates background work without blocking the user.
The trends of sub-agents has shifted from specialized to generic, but regardless of your chosen approach, each system (or harness if you will), needs to have three core patterns for working with sub-agents.
As I developed a general purpose agent that runs anywhere, I naturally reached for sub-agents to solve some key problems, but ran into some limitations with the standard pattern for agents: the synchronous sub-agent.
When orchestrating sub-agents, there are three key patterns to get in place. Here's what they are, when to use them, and ideas on how to implement them.
What a Sub-Agent Is (and Why It Exists)
A sub-agent is a separate LLM execution context spawned by a parent agent to handle a scoped task. The parent describes the task, provides tools, and gets back a result. The sub-agent should run in its own context window so it doesn't pollute the parent's.
As I covered in an earlier post, the primary purpose is context compression. The Cursor team also described this in their recent Latent Space interview. Sub-agents exist so the parent never has to absorb the full trajectory of a delegated task. The sub-agent might read 8 files and make 15 tool calls. The parent sees a 750-token summary.
During my own testing with the utah project, sub-agents resulted in 90%+ reduction in tokens added to the parent agent's context.
That's the real ROI. Not parallelism, but context management. The parent stays lean and can handle more tasks in a single conversation without hitting context limits or degrading response quality.
The role of a sub-agent
Sub-agents can cover a variety of use cases in any agentic system. Sometimes the parent agent just needs to run a sub-agent like it uses a tool, to execute a task and return the result back. Other times, it has a concrete task that can be fanned out and finish later, clearing the main agent loop. And lastly, sometimes the parent agent needs to perform a task at a later time like at the end of the day or week. These are the three core patterns for sub-agents:
- Sync - "Do this and wait"
- Async - "Go do this, report back"
- Scheduled - "Do this later"
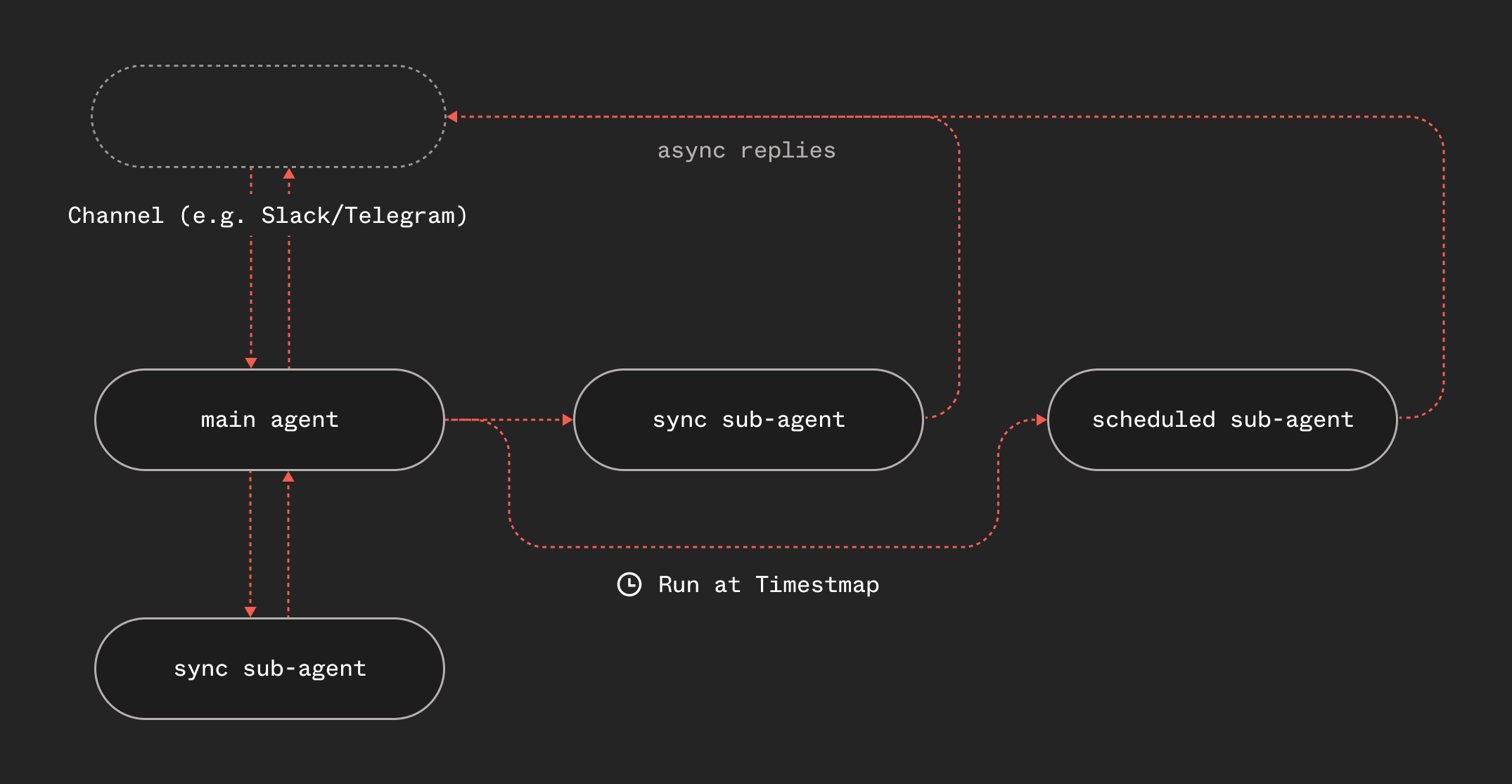
Every agentic system needs all three and they all have their own purpose and considerations. For implementation details, see the sub-agent delegation guide. Let's dive into each of them.
Pattern 1: Sync — "Do this and wait"
The parent spawns a sub-agent and blocks until the result comes back. The sub-agent runs, does its work, and returns a summary as a tool result.
When to use it: The parent needs the answer to continue. Data lookups, analysis, code generation that feeds into the next step, anything where the response shapes what happens next.
const subResult = await step.invoke("sub-agent", {function: subAgent,data: {task: "Read the following 8 files and create a summary of the sub-agent architecture with code examples",subSessionKey: `sub-${sessionKey}-${Date.now()}`,},});toolResult = { result: subResult?.response || "(No response)" };
Within our system, step.invoke() is function-to-function RPC with durability. The parent checkpoints before invoking, so it won't re-invoke on retry. If the sub-agent crashes, Inngest retries it. The parent just waits.
The tradeoff: The result enters the parent's context window. But it's a summary, not the full trajectory: that 90%+ reduction means the parent can delegate many times before context becomes an issue.
Think of sync sub-agents as function calls. You call, you wait, you get a return value.
Pattern 2: Async — "Go do this, report back"
The parent fires off a sub-agent and continues the conversation immediately. The sub-agent runs independently and replies directly to the user when it's finished.
When to use it: Long-running research, report generation, drafting, analysis — anything with side effects that don't need a return value. This should be your default.
await step.sendEvent("spawn-async-sub-agent", {name: "agent.subagent.spawn",data: {task: "Research competitor pricing and compile a report...",async: true,channel,destination,channelMeta,},});toolResult = {result: "Async sub-agent spawned. It will reply directly to the user.",};
The parent doesn't wait. The sub-agent is a completely separate function run. When it finishes, it emits an event with the response and channel routing info — the reply gets delivered to the user through whatever channel originated the request.
The tradeoff: The parent can't incorporate the result. If you fire three async sub-agents, each runs in total isolation. That's a feature, it's zero coordination overhead, parallel execution for free, but it means the parent can't synthesize across them in the same turn.
The next iteration: The parent agent should still be able to query child agent output and context within your system using either the session or conversation ID or an ID returned from the scheduler (ex. an event ID in Inngest). In essence, this is a "handle" on the task that the agent can choose to check up on later.
Think of async sub-agents as colleagues. You hand off work, say "let me know when it's done," and move on. Multiple async sub-agents can run simultaneously with no coordination code.
Pattern 3: Scheduled — "Do this later"
The parent schedules a sub-agent to run at a specific future time. This is the one most people miss, and it's the most interesting.
When to use it: Follow-ups, reminders that should be smart, recurring checks, anything where "later" should mean "with fresh data at execution time."
await step.sendEvent("spawn-scheduled-sub-agent", {name: "agent.subagent.spawn",data: {task: "Pull the deploy metrics from the last 24 hours and send a summary...",async: true,channel,destination,channelMeta,},ts: new Date("2026-03-10T14:00:00Z").getTime(),});
Same sub-agent function. Same event. Just with a ts timestamp for delayed delivery.
What makes this different from cron: "Remind me to check the deploy metrics tomorrow at 9am" doesn't send a notification at 9am. It runs an agent at 9am that actually pulls live metrics and sends the analysis. "Send a follow-up email to this thread on Monday" runs a sub-agent Monday with full thread context, not a scheduled message composed on Friday.
Scheduled sub-agents are dynamic, context-aware, and run with the current state of the world at execution time. No new infrastructure beyond what async already provides — it's the same function, same handler, same delivery mechanism. The only difference is the ts field on the event.
The tradeoff: You can't easily cancel or modify a scheduled sub-agent after it's been queued. And the task description is frozen at scheduling time — it captures the parent's understanding of the task now, which may be stale by execution time.
The next iteration: Similarly to the async sub-agent approach, the parent agent can get a handle on the scheduled task and now has this in it's own context and memory. It can then query the system itself to know what is due to run, cancel it, and check it's status.
Decision Framework
- Need the result to continue? → Sync
- Independent task, no blocking needed? → Async
- Multiple independent tasks? → Async (parallel)
- Should happen at a specific future time? → Scheduled
- Not sure? → Default to async. It's cheaper and keeps the parent lean.
Don't choose for the model. Give it all three tools with clear descriptions. It picks correctly.
Our implementation
One function, three modes
In our implementation, we leverage one re-usable Inngest function that handles sync, async and scheduled. The difference is how it's triggered and where the result goes.
Here's the entire sub-agent that handles all three patterns:
export const subAgent = inngest.createFunction({id: "agent-sub-agent",retries: 1,triggers: [agentSubagentSpawn],},async ({ event, step }) => {const {task,subSessionKey,async: isAsync,channel,destination,channelMeta,} = event.data;const framedTask = isAsync? `You are an async sub-agent. Your response goes directly to theuser. Be thorough.\n\n${task}`: `You are a sub-agent. Your response goes back to the parent asa summary. Be concise.\n\n${task}`;const result = await createAgentLoop(framedTask, subSessionKey, {tools: SUB_AGENT_TOOLS,isSubAgent: true,})(step);if (isAsync && channel && destination) {await step.sendEvent("async-reply", {name: "agent.reply.ready",data: {response: result.response,channel,destination,channelMeta,},});}return result;});
The framing instruction is the key differentiator. Sync sub-agents are told to be concise (the parent synthesizes). Async sub-agents are told to be thorough (they're the final word to the user). Scheduled sub-agents are just async with a delayed trigger — no special handling needed.
Two tools, not one
const delegateTaskTool: Tool = {name: "delegate_task",description: `Delegate a self-contained task to a sub-agent that runsin an isolated context window. Use this when:- The task requires many file reads/edits (4+ tool calls expected)- The task is independent and can be described as a clear goal- You want to keep your own context leanThe sub-agent has access to the same workspace and tools but its ownconversation. You'll receive a summary of what it accomplished.`,parameters: Type.Object({task: Type.String({description:"Clear, detailed description of what the sub-agent should do.",}),}),};
Why two tools instead of one tool with a mode parameter? Models are better at tool selection (picking from a list) than parameter optimization (reading parameter descriptions and choosing correctly). Separate tools = cleaner logs, clearer traces, easier debugging.
Tool sets and depth control
export const TOOLS: Tool[] = [...piTools,rememberTool,webFetchTool,delegateTaskTool,delegateAsyncTaskTool,];export const SUB_AGENT_TOOLS: Tool[] = [...piTools, rememberTool, webFetchTool];
Depth-1 delegation. Sub-agents get the same workspace tools but can't spawn sub-agents. No routing logic. No task classification. The model reads the tool description, decides when delegation makes sense, and writes a natural language task description.
The agent loop
Since the agent leverages our agent loop using Inngest steps, it's durable and if a step fails, it retries from where it left off rather than from the beginning of the loop. As these sub-agents are just tools, the result is just appended to the messages just like any tool call is.
Channel-agnostic routing
Message arrives (Telegram, Slack, email)→ parent agent processes, decides to delegate async→ spawn event carries { channel, destination, channelMeta }→ sub-agent finishes, emits reply event with same routing info→ send-reply function dispatches to correct channel handler
The sub-agent doesn't know about Telegram or Slack. Adding a new channel is a handler, not a sub-agent change. This is important as it means the three patterns work identically regardless of where the user's message came from.
The Primitives That Make This Work
| Pattern | Inngest Primitive | What it does |
|---|---|---|
| Sync delegation | step.invoke() | Call sub-agent function, wait for result |
| Async delegation | step.sendEvent() | Fire sub-agent event, don't wait |
| Scheduled delegation | step.sendEvent() + ts | Fire sub-agent event at a future time |
| Sub-agent execution | createFunction() + event trigger | The sub-agent itself |
| Every LLM call | step.run() | Durable checkpoint — crash recovery mid-loop |
| Result reporting | step.sendEvent() | Sub-agent reports completion |
User → Parent Agent (agentic loop)├── [sync] step.invoke() → Sub-Agent → result back to parent├── [async] step.sendEvent() → Sub-Agent → reports to user directly└── [sched] step.sendEvent({ts}) → [delayed] → Sub-Agent → reports to user
Durability runs through the entire chain. No custom orchestration code. No state machines. No queue management. It's a while loop with step wrappers.
Failure handling falls out naturally. Sync failures: the sub-agent retries via Inngest, step.invoke() throws if retries are exhausted. Async failures: a global inngest/function.failed handler catches it, and the channel routing info lets it notify the user.
The benefit of this is that the orchestration layer can handle all of these parts, keeping you flexible to iterate on your harness or agentic system. Patterns, models and approaches move fast, so flexibility is really valuable to move fast.
Why Generic Beats Specialized
Once you have the three patterns, there's a tempting next step: build specialized agents for each domain. An email agent, a data agent, a coding agent, each with its own tools and prompts. Don't dive into this temptation right away.
Internally, we've built systems with specialized agents and a custom router between them. The routing layer became more complex and with the progress with models, this specialization has felt far less important and honestly a cumbersome layer to maintain in most setups.
Some things to keep in mind:
Tool overlap. With how good general purpose agents are with coding tools or patterns like tool search, tool discovery, skills, sometimes a whole library of many tools separated by agent may not be what you need.
The routing paradox. You need something to decide which specialist handles each request. Hard-coded routing can break on ambiguity. LLM-as-router adds latency and a new failure mode. If your routing LLM call is smart enough to pick the right agent, couldn't it just do the task itself? That looks just like a general purpose agent with a "task" delegated to it to me.
The "wrong agent" problem. When the router sends a task to the wrong specialist, the failure mode is uniquely bad. The wrong agent attempts the task with incomplete capabilities and might partially succeed in a subtly wrong way. The system trusts the response because it came from the designated specialist. These are weird failure cases to handle or plan for.
Eval surface explosion. With N agents you need N individual eval suites, 1 routing eval suite, O(N²) pairwise interaction tests, and end-to-end integration tests. A single generic agent needs one eval suite covering all capabilities. If you're doing something like this I'd actually love to chat or learn from what folks are doing - send me your own blog post or approaches.
I'm not unique in these opinions either. Anthropic's "Building Effective Agents" paper touches this topic:
"Consistently, the most successful implementations weren't using complex frameworks or specialized libraries. Instead, they were building with simple, composable patterns."
In the podcast I mentioned above (go listen to it), the Cursor team described using "a mostly generic task interface where the main agent can define what goes into the subagent." Sub-agents as context compression boundaries first, parallelism second. The model defines sub-agents at runtime, not the developer at build time.
It's kinda funny how software has seen similar patterns before in other ways. The explosion of microservices then the pull back of them towards modular monoliths. The overhead started to outweigh the benefits. Generic agents are similar.
When specialization does win
- Different model requirements. One task needs vision, another needs fast classification, route to different models.
- Security boundaries. Agent A accesses customer data, agent B only accesses public data.
- Regulatory requirements. Some domains require auditable, separate processing pipelines.
- Proven eval-driven evidence. Your evals show a specialized agent consistently outperforms generic on a specific task.
The key principle: specialization should be driven by measured necessity, not architectural aesthetics. Start generic. Specialize when it makes sense.
What we're exploring next
The approach that we're using today to build our systems is generic and works for all three modes: sync, async, and scheduled. These are some things that we'll be exploring next as these primitives:
- Self-iterating agents. With scheduled sub-agents, why couldn't the agents keep iterating on themselves and the systems. Cost and budgets will naturally come into consideration.
- Orchestration-awareness. Async and scheduled sub-agents return their event ID. With APIs and context, the any agent or sub-agent in the system could be aware of what's running, where, go fetch status, results. It becomes less of a loop + fan-out and more of a web.
- Callbacks and other patterns. The current reference example uses the channel as the callback mechanism when work is done, but what could a generic sub-agent system look like with different types of callbacks, e.g. update a Linear task, store a reference of the research or report in a database. Tools can be used for this, but callbacks provide some level of guarantee.
Wrapping up
These three sub-agent patterns all have their use cases and combine quite nicely in different types of agentic systems or harnesses. If you can model them out just as tools in your own system and leave the work to the orchestrator, you can quickly iterate on your product. Avoid the temptation of specialization, just start here and ship it.