Inngest's ephemeral state store manages state for all currently active function runs. We operate a sharded Redis cluster to handle this, and the system is constantly hammered by reads and writes. For a while, our answer to growing pressure on the state store was simple: add more shards. But, there was a catch.
Each new shard came with real operational overhead: provisioning one takes hours, slot rebalancing has to complete before it meaningfully helps with load, and every shard is a large memory- and disk-heavy instance with a non-trivial cost.
For some time we had been experiencing I/O timeouts in this system that affected reliability for customers, usually in the form of increased latency rather than outright errors, since these operations can be retried safely thanks to idempotency. In some cases the timeout occurred after the operation had already committed, which is the worst kind of failure mode because from a caller's perspective the operation appears to have failed, even though it may have actually succeeded. That ambiguity forces the system to retry defensively and rely on idempotency guarantees to avoid duplicating work.
We needed to improve this quickly, but the state store was tightly coupled with several other services. The first step was introducing a better abstraction: a clear interface for how services manage run state. Along the way we realized we could also significantly reduce load if we shifted the access pattern slightly. We introduced a new state proxy service, the only gRPC service that talks directly to the state store, which also acts as a caching layer for state.
[ fig. 1 ] — Architecture: before / after proxy
%20(1).svg)
Why "just add a shard" stopped working
Our Redis cluster was both read- and write-heavy. Scaling writes with more shards helped for a while, but it didn't address the read pressure at all. Executors repeatedly fetched event data and step inputs/outputs they had already read earlier in the same run, which meant Redis was serving a large number of redundant reads.
What we really needed was to change the access pattern. Not because Redis reads are slow (they are extremely fast), but because reducing the total number of operations would both lower pressure on the cluster and give us more flexibility in the storage backend we might use in the future.
Key Insight: Although run state as a whole is mutable, many of the highest-read pieces of that state are immutable once written. In particular, triggering events and step inputs/outputs do not change, which made aggressive caching possible without complex cache invalidation.
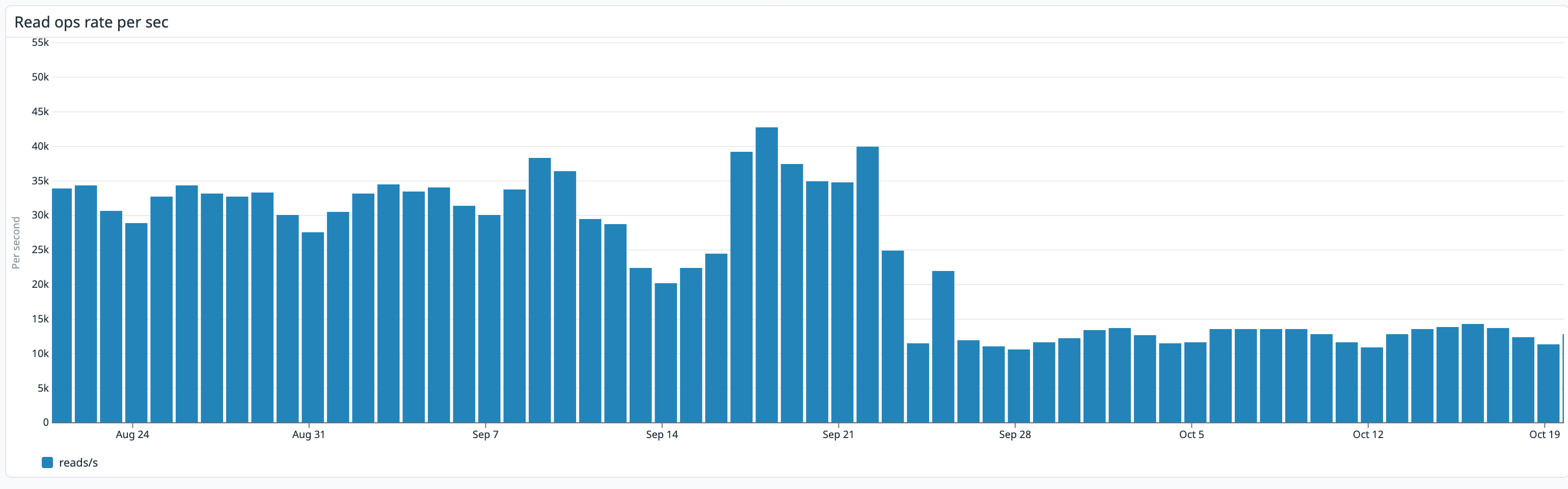
[ fig. 2 ] — Redis read operations: before vs. after proxy rollout
%20(1).svg)
Proxy design: consistent routing and headless load balancing
The proxy is a standard Kubernetes Deployment sitting between all services that interact with the state store and Redis. Every read and write goes through it.
The routing logic is critical. To maximize cache hits, requests for a given run's state must consistently land on the same proxy node, since that's where its cache entry lives. We achieved this with consistent hashing based on run ID at the gRPC layer, using a headless Kubernetes service to expose pod IPs directly to clients.
Consistent hashing also makes the system resilient to cluster size changes. When nodes are added or removed, only a small portion of keys need to be remapped to different nodes, which preserves most of the existing cache locality while naturally rebalancing the load.
Headless services in Kubernetes bypass the cluster's default virtual IP load balancing. Instead, DNS resolves to the individual pod IPs, which lets clients implement their own load balancing strategy. We used gRPC's ringhash load balancer, which at the time was available in an experimental form that didn't require xDS.
[ fig. 3 ] — Consistent hashing: run ID → proxy node → cache
%20(1).svg)
Cache design: exploiting immutability boundaries
The main question for the cache layer was simple: what can we cache safely? Once we mapped the data's mutability boundaries, the answer was fairly straightforward.
Events that trigger a function run are written once and never change. Step inputs and outputs are written once per step and never change as well. These can be cached freely and never need invalidation. They live on the proxy node's local cache until the node is recycled.
The execution stack and run metadata are mutable. They change with each step execution. We route reads for these directly to Redis. We considered caching the stack with validation against metadata, but the stack is capped at 1000 entries (the maximum number of steps a run can have) and fetching it directly from Redis proved cheap enough in practice. The added complexity wasn't really worth it.
[ fig. 4 ] — Cache routing: immutable vs. mutable state
.svg)
Why PebbleDB won over Badger
For the caching layer, we shortlisted and benchmarked both PebbleDB and Badger, and their raw performance was comparable. Either would have worked from a throughput perspective. The difference showed up in allocations per operation: PebbleDB performed significantly fewer allocations, which reduces pressure on Go’s garbage collector and results in a more predictable memory footprint under load.
Configuration flexibility also helped. We disabled the WAL entirely (DisableWAL) since we don't need recovery after pod restarts or rollouts. Increasing memtable sizes (MemTableSize) and raising the MemTableStopWritesThreshold before write stalls improved write throughput as well.
PebbleDB is also already used elsewhere in the system for caching pauses, which made it a small additional factor in favor of keeping things consistent.
Rolling out safely with shadow mode and feature flags
We didn't switch everything over at once. The rollout happened in phases so we could build confidence gradually and roll back surgically if needed.
[ fig. 5 ] — Staged rollout: shadow mode → per-account flags → full cutover
.svg)
Shadow mode was worth the extra setup. In this mode, the proxy reads from the cache and compares the result against the source of truth for consistency checks, but discards the cached value instead of serving it to the caller. This lets us validate cache correctness using real production traffic without affecting live requests. The shadow read runs asynchronously and only reports discrepancies via logs and metrics, so it does not impact request latency. Once the behavior looked solid, we enabled the proxy behind per-account feature flags.
That gave us a safe rollback mechanism. When we hit one issue significant enough to warrant reverting, we were able to disable the proxy for the affected account immediately rather than rolling back the entire deployment.
After the rollout completed, all accounts were routed through the proxy. gRPC interceptors and retry policies now handle the I/O timeouts that can occur at different layers, giving us better observability and more control over failure modes at the proxy layer.
[ fig. 6 ] — Inngest observability dashboard — Gradual rollout of state proxy

Results: what actually changed
Redis read operations dropped from ~42,000/sec to ~14,000/sec. That's a 67% reduction. Network overhead for state operations traveling from our cluster to AWS also reduced significantly.
We didn't eliminate I/O timeouts entirely. We monitor and handle them better now in the gRPC layer through retry interceptors, and the proxy gives us clearer visibility into where failures occur. Previously, a Redis timeout was difficult to attribute. Now it is surfaced at the proxy layer.
The most important outcome is abstraction. The proxy hides the storage backend behind a clean API. When we migrate to a more scalable database without Redis's single-threaded I/O limitations, no other service needs to change. That migration is already in progress.
[ fig. 7 ] — Chart shows Redis read ops before/after proxy rollout
A few things worth noting for similar work
The immutability insight was the highest-leverage part of this whole project. Before writing a line of proxy code, it's worth mapping every read operation and asking: how often does this value change? For event-driven systems specifically, a lot of data is written once and referenced many times. That's a very cacheable access pattern, and most systems don't fully exploit it.
The headless service + ringhash combination gives consistent routing without requiring a distributed cache. The routing logic lives in the gRPC client while the Kubernetes headless service handles discovery. It is simpler than it sounds. One thing to watch for is scale-out detection: set max_connection_age on gRPC connections so clients periodically re-resolve DNS and pick up new proxy nodes.
On the rollout side: shadow mode is worth the overhead if your proxy is sitting in a critical data path. The incremental per-account rollout was what gave us operational confidence. We could see real-world behavior for a subset of traffic before committing fully.
If you're hitting similar read pressure on a stateful system and want to talk through the approach, feel free to reach out in the Inngest Discord.