
We're thrilled to release today a new capability of Inngest's orchestration engine: Checkpointing. By enabling checkpointing, Inngest workflows keep durability while achieving near-zero inter-step latency.
Running in production over the last month, we've observed a 50% increase in execution speed over 9 workflows, dropping inter-step latency to tens of milliseconds (with a sample size of 100K executions):
“ Today we opened the pipes! Using Inngest's Checkpointing, we managed to bring down the time to process a Shopify order from around 18 seconds to around 5 seconds. In a world where we are processing millions of transactions per day these wins really add up! ”
Durability, initially designed for background workflows, comes with the cost of inter-step latency to durably persist state, which impacts the swiftness of the user experience.
The rise of AI use cases involving the combination of an interacting user experience and slow and unreliable LLM calls forced many developers to favor low latency at the expense of durability.
Checkpointing introduces a hybrid durable execution mode where synchronous steps that require suspending the execution (ex, step.run()) are durably executed without inter-step latency.
Developing reliable and low-latency workflows is no longer an “All-or-nothing” choice.
Checkpointing: under the hood
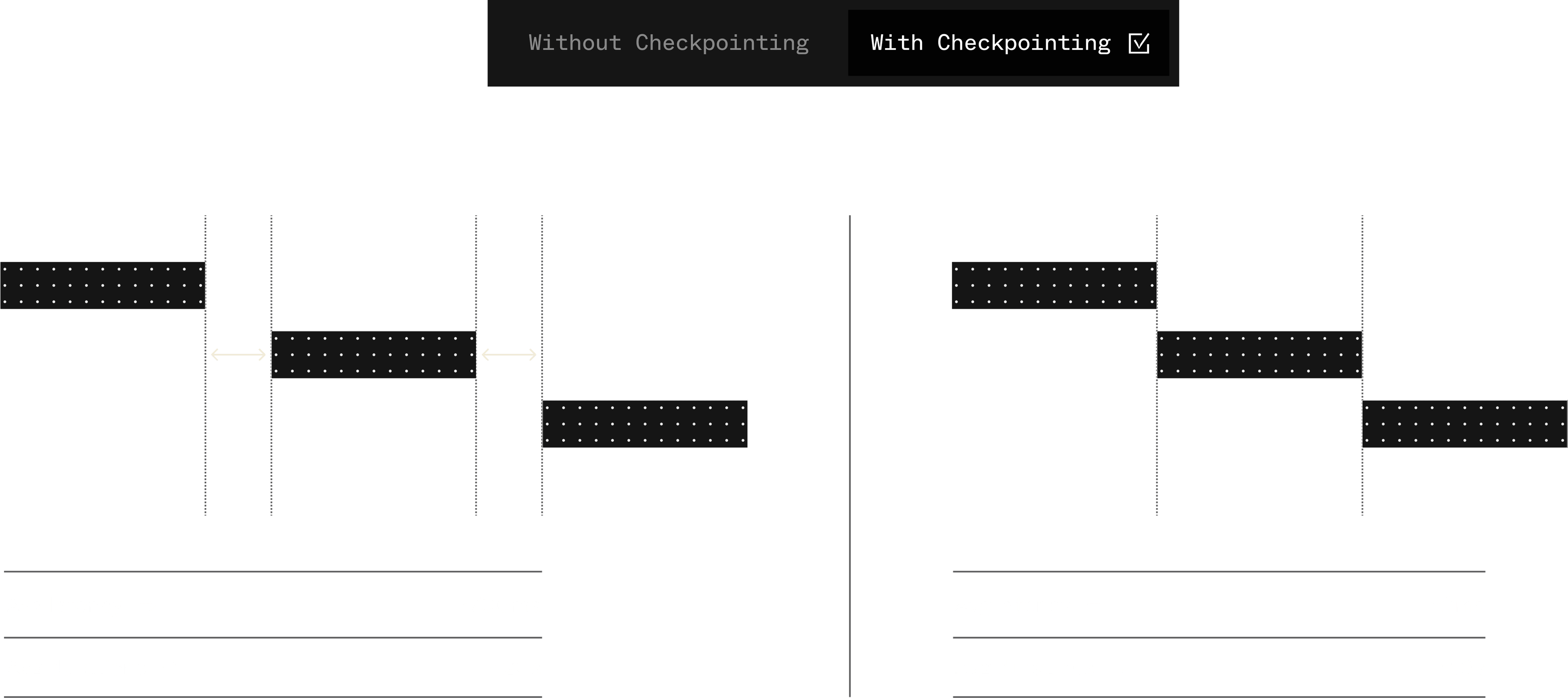
Without checkpointing, each step returns an HTTP response with the step output to Inngest, then we enqueue another job for the next step. This is another HTTP request, resulting in inter-step latency. While this is safe (as every step has its own fresh request), it's also not very performant.
With Checkpointing, synchronous steps such as step.run() run immediately, then save their output via an API, significantly improving efficiency and reducing latency. The SDK then moves on to the next step immediately.
SDKs move from step to step for synchronous steps (ex, step.run()), falling back to Inngest's async executor for asynchronous steps (ex, step.sleep()) - or if your checkpointing request fails due to, for example, a transient networking error. This dual-stack setup ensures that your workflows can handle all steps effectively, without any safety penalty.
This division reduces inter-step latency and improves performance by minimizing unnecessary roundtrips.
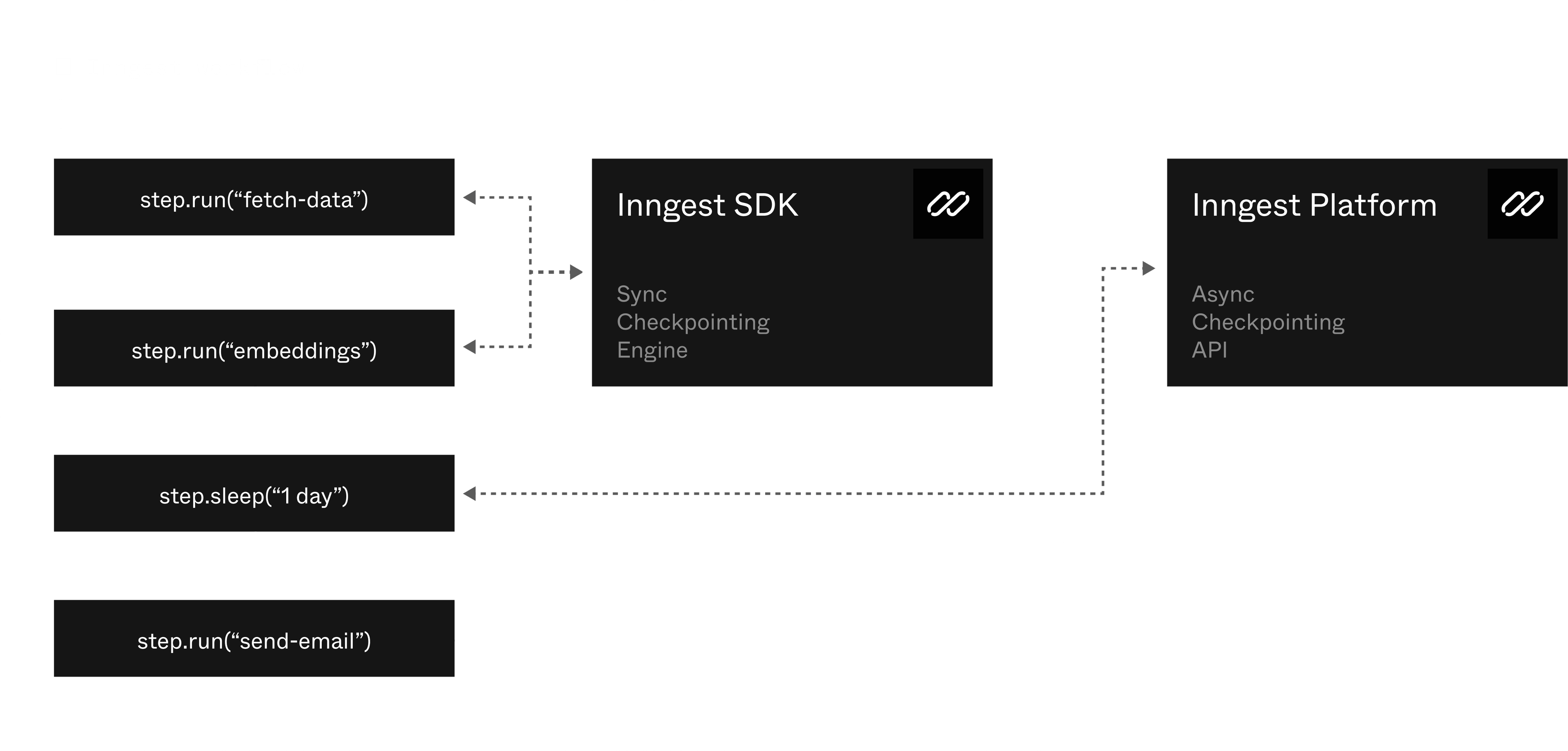
Checkpointing acts as a safeguard to prevent re-running steps or losing state. The Checkpointing API ensures that the state is preserved and execution continues smoothly. The system is designed to be robust and idempotent, providing reliability and performance. This means that even if interruptions occur, the state is preserved, and execution can resume seamlessly. The Checkpointing API is fully idempotent and includes client retries to handle failing requests early and resolve potential issues.
Working with serverless
Inngest runs everywhere, on both servers and serverless. To respect serverless timeouts, Checkpointing includes its own tunable maximum lifetime. Inngest will only continue from step to step if we're within this lifetime. As soon as the lifetime is hit, the next step will trigger another async execution, creating another HTTP request for the next step - resetting the serverless function's execution time.
Enable Checkpointing Today
Checkpointing is now available in public beta, configurable at the client-level:
import { Inngest } from "inngest";const inngest = new Inngest({id: "my-inngest-app",checkpointing: true,});
or at the function-level:
inngest.createFunction({id: "my-inngest-workflow",checkpointing: true,},{event: "demo/event.sent",},async ({ event, step }) => {// ...},);
The reliability you expect from Inngest doesn't change. Steps are still durable. Failures still trigger retries. You still get full observability into what happened and when.
Checkpointing removes the execution delays without sacrificing any of the guarantees that make durable execution valuable.


