
At Inngest, we run scheduled functions on behalf of thousands of users. For a long time, we managed this with an architecture that worked well enough, until it didn't.
This is the story of how we used our own queueing infrastructure to rearchitect cron scheduling from a fragile polling loop into a durable, self-healing, horizontally scalable distributed scheduler.
Why polling a database for scheduled functions breaks at scale
Our original cron service was straightforward. On startup, it loaded all scheduled functions from the database. Every 60 seconds, it refreshed that list to pick up newly registered functions and remove ones that had been paused or deleted. For each function, it registered a job with an in-memory cron manager that would fire the execution at the right time.
This worked for a time, until usage really started to climb. The base query cost grew with the number of scheduled functions. When the database slowed down even briefly, jobs missed their window. And because we kept all schedule state in memory, any process crash wiped it entirely.
While we tackled fault tolerance by running two replicas of our legacy cron service doing the exact same work and relied on job idempotence to prevent duplicate executions, the existing architecture had a hard ceiling. Adding a third instance would neither improve reliability nor help with higher scale.
What started as an occasional reliability issue became a structural one: the polling approach was getting slower as the platform grew and any database hiccup could cause users' functions to miss their scheduled time entirely.
Inngest Queues: A Primer
At the core of Inngest's execution model is a custom-built queueing system. It was designed from the ground up to handle the demands of a multi-tenant durable execution: fairness across tenants, priority scheduling, high throughput, and native support for the flow control mechanisms like debounce, batching, rate limiting.
Everything in Inngest that involves scheduling or executing work runs through this queue system. It is the backbone of the platform.
We run two classes of queues, both built on the same underlying infrastructure. User function queues carry the jobs that execute functions in response to events, the engine behind every function run. We also operate a distinct set of system queues to orchestrate Inngest's time-based flow control and scheduling mechanisms. When a function is debounced, a system queue job fires after the timeout to trigger the delayed execution onto the user function queue. When a function uses batching, system queues manage the flush after the batching window expires. Lifecycle changes triggered by user actions like pausing and unpausing functions and background maintenance tasks like migrating users across shards all run through system queues as well.
Because so much of Inngest's behavior is inherently time-based, these queues were built with the properties you need for reliable scheduling:
- Durability: Jobs are persisted in the queue, not held in memory. A process crash doesn't lose any work, jobs survive and get picked up by another consumer process.
- Delayed job support: System queues already supported scheduling a job to fire at a specific future time, a prerequisite for debounce and batch window timeouts.
- Delivery guarantees: The queue already handled retries, failure recovery, and the deduplication logic needed to prevent double execution.
How system queues replaced polling as the scheduling layer
Cron scheduling is fundamentally a time-based orchestration problem, and system queues were already Inngest's solution to every other time-based orchestration problem. The new cron architecture didn't need to invent anything new. It just needed to use what was already there.
The new architecture is built around one idea: instead of frequently scanning the database to discover what should run, each scheduled function maintains exactly one pending job in the system queue. That job represents its next scheduled execution. When it fires, it schedules the one after it.
The result is a continuous cycle that runs entirely on the queue.
A self-scheduling cron cycle
Starting the cycle. When a function is registered or updated, the user-facing API server enqueues a job into the "cron-sync" system queue with the function ID and its cron expression. A lightweight handler consumes this job and bootstraps the cycle by scheduling a job in the "cron" system queue a few seconds ahead of the function's next scheduled time.
Running the cycle. Each cron job is enqueued a few seconds before the actual scheduled time, giving the queue time to prefetch and warm up before the trigger moment arrives. When the job fires, the cron handler does three things:
- Validates that the function is still active and that its schedule has not changed
- Enqueues the function run onto the user function queue for the exact scheduled time
- Enqueues the next cron job back into the system queue for the following scheduled time
Breaking the cycle. When a function is paused or archived, the handler skips both enqueue steps. Nothing is written to the user function queue. No follow-up job is written back to the system queue. The cycle stops cleanly. When the function is unpaused, the API server restarts the cycle - exactly as it does for a freshly registered function.
Schedule state is now explicit and durable. At any point, the cron system queue is a precise, persistent record of when every function is next scheduled to run.

Automatic recovery for broken cycles
No system is immune to unexpected failures. To guard against broken cycles going silent, we added a periodic cron health checker.
The health check job scans for functions that should have a pending cron job but do not. If a cycle has broken for any reason, the health checker writes a new cron job to restart it without any human intervention.
Under normal operation, the health checker finds nothing to fix. It exists to future-proof the design against unintentional bugs or new failure modes.
How we migrated thousands of live cron jobs without dropping a single execution
We had thousands of per-minute cron jobs running continuously. Any gap in coverage would be immediately visible to users.
The migration relied on one property: the new system generates cron job IDs using the same deterministic logic as the old one. Both systems could run simultaneously without risk of double-execution or missed executions, enabling a two phase rollout: Enable the queue based crons first, then decommission the polling service. The idempotency layer that the old system had always relied on became the bridge between the two.
We used feature flags to control rollout at an account level. Pilot accounts were selected to cover a range of cron usage patterns: some with a handful of schedules, others with heavy usage across many functions and workspaces. This gave us real signal on both correctness and performance before expanding to the broader fleet.
Once pilot accounts ran cleanly, we expanded swiftly, monitoring schedule reliability and queue health at each step.
Results
Cron jobs now run through the same system queues as every other internal operation, we get full observability into the scheduler's state for free - the queue is a live, inspectable record of exactly which functions are scheduled, when they will fire, and whether any cycles are broken.
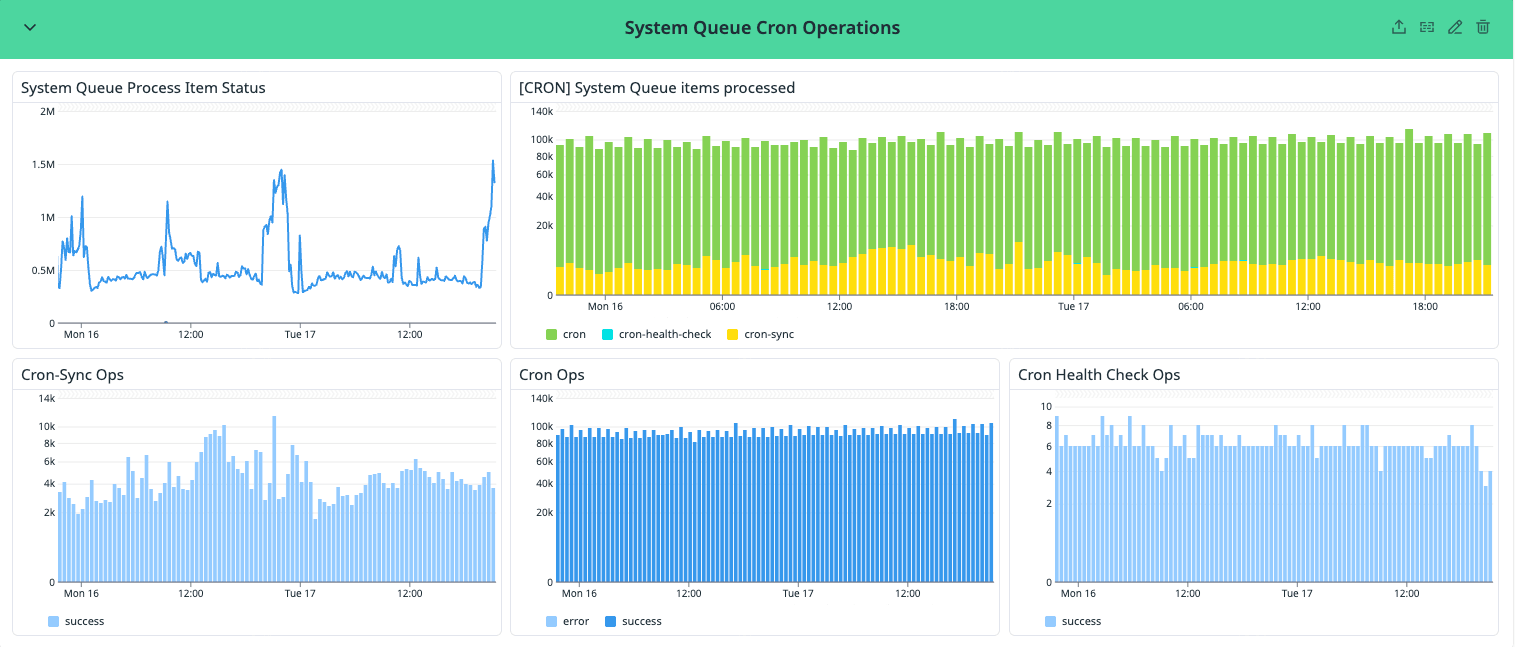
Cron scheduling became just another job type on infrastructure the team already operated, monitored, and trusted. No new services to deploy, no new failure modes to learn, no separate on-call runbook.
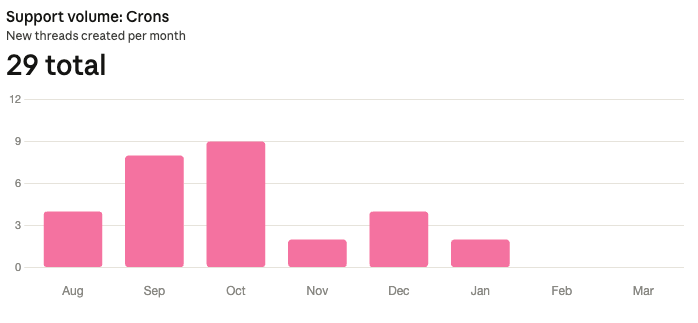
The reduction in cron-related support volume tells the rest of the story:
If you want to see how Inngest handles durable scheduling, batching, and event-driven workflows, you can get started at inngest.com.


