
Support tickets are deceptive.
Some of them are genuinely easy: a missing config value, a misunderstanding about concurrency, a common integration mistake. But easy does not mean low risk. A wrong answer still burns customer time, erodes trust, and often creates a second round of support work.
We did not want a bot that simply saw a ticket and started typing.
We wanted a bot that investigates the way a support engineer would investigate: read the thread, search the docs, look for similar past cases, gather sources, and only then draft a reply.
That distinction ended up mattering more than the model choice.
The useful part of the system is not that it can generate text. The useful part is that it can assemble context from the same places a human would look first.
Investigation, not autocomplete
The failure mode of most support automation is straightforward: the model sounds confident before it is grounded.
That usually happens because the system treats support like a pure generation problem. Take the incoming ticket, add a prompt, maybe stuff in some docs, and hope the model can synthesize a correct answer.
That approach breaks down quickly.
- The current thread may be missing important context if you only look at the latest message.
- The docs may contain the answer, but not in the exact words the customer used.
- The best answer may already exist in a previous ticket that never made it into documentation.
So we built the bot around three sources of truth:
- The live support thread.
- Historical tickets that are semantically similar.
- A local copy of the Inngest docs that the agent can search directly.
The job of the bot is to pull useful context from those three places, then draft an internal response that a human can review.
That last part is important. This system is for initial investigation and draft creation, not automatic customer-facing replies.
The architecture in one pass
At a high level, the system is just a small event-driven workflow.
When a ticket reaches the bot, an Inngest function starts an investigation run:
- Fetch the full conversation from Plain.
- Extract the core customer question.
- Search a vector index of historical tickets.
- Run a documentation-search agent over the local docs corpus.
- Combine the evidence into a draft reply.
- Post that draft back to the support thread as an internal note.
That workflow lives behind a single Inngest endpoint, but it is really doing two different jobs.
The first job is live investigation on an incoming ticket.
The second job is continuously building the memory layer that makes historical search useful in the first place.
How a ticket investigation runs
The investigation workflow starts from a Plain thread event.
The first step is not prompting a model. It is fetching the full thread conversation. That sounds obvious, but it matters. Support tickets are usually conversations, not one-shot questions. The first customer message often contains the cleanest description of the issue, while later messages add failed attempts, workarounds, and clarifications.
Once we have the full thread, we extract the first meaningful customer-authored content and use that as the core question for retrieval.
From there, the workflow splits into two research paths.
Path one: similar tickets
We generate an embedding for the ticket and search PostgreSQL with pgvector for semantically similar historical tickets.
This gives us something support teams rarely have in a clean, searchable form: precedent.
Not just keyword matches, but tickets that look like the current issue even when the wording is different.
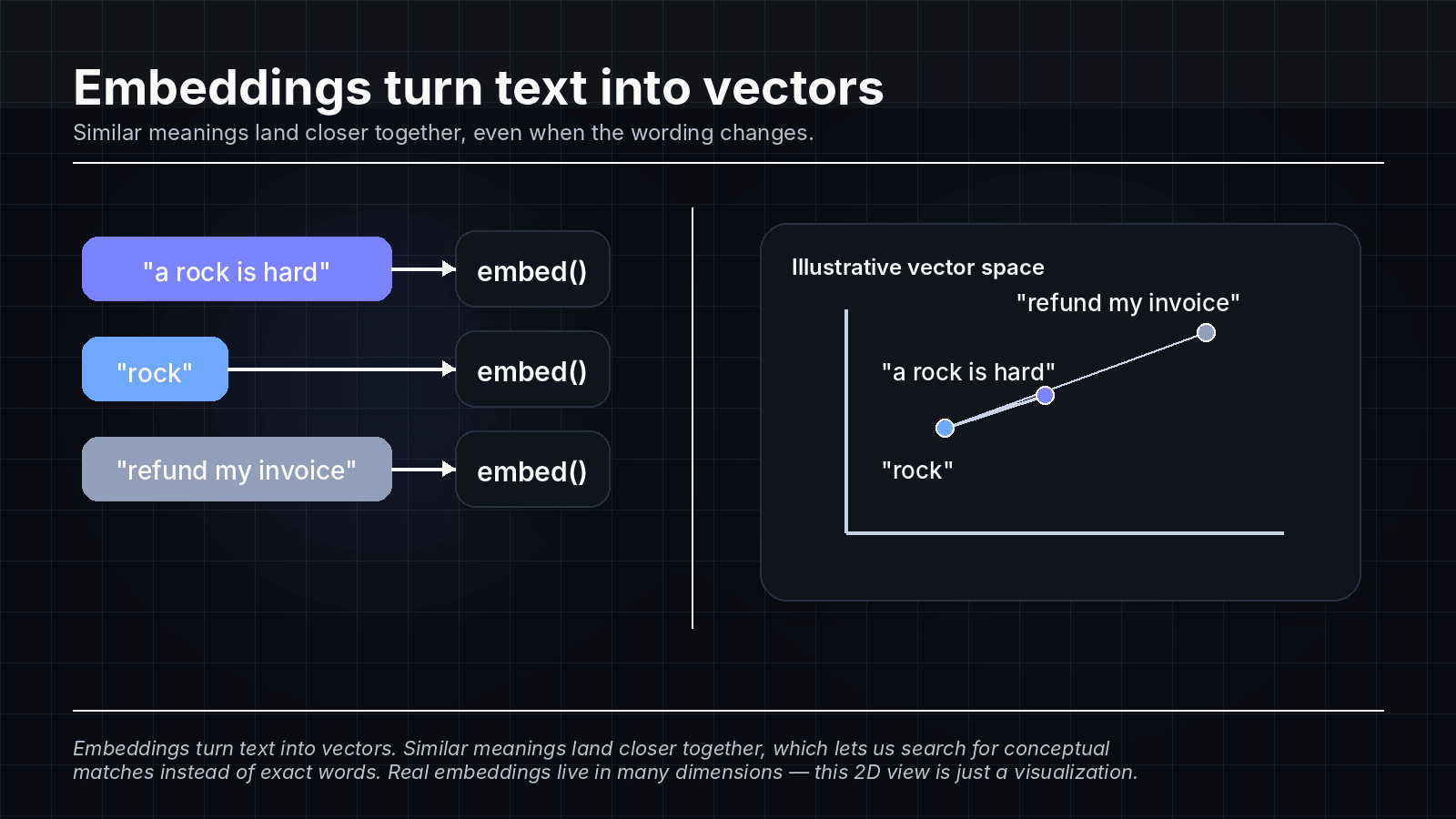
In simple terms, an embedding turns a piece of text into a long list of numbers: a vector. You can think of that vector as a point in mathematical space. If you embed "a rock is hard" and then embed "rock," those two points will usually end up closer together than either one would be to something unrelated like "refund my invoice."
Once both the current ticket and past tickets have been turned into vectors, the database can measure the distance between them and return the nearest matches. That is what lets us search for conceptual similarity instead of exact wording.
If we find relevant matches, we fetch the full conversation for those tickets from Plain as well. That lets the bot see how a similar issue was actually resolved instead of only seeing a shallow summary or a title.
This turned out to be one of the highest-leverage parts of the system.
Documentation tells you what should happen.
Historical tickets tell you what actually confused people, what misconfigurations recur, and what explanations have already worked in practice.
Path two: docs search
At the same time, we run a small search agent over a checked-out copy of the Inngest docs.
We intentionally did not solve this by shoving a giant documentation dump into the prompt.
Instead, the agent gets a small set of tools:
grep_searchto search contentglob_searchto find candidate filesread_fileto inspect promising docs in full
That gives the model a much better shape of problem.
It does not need to memorize the docs. It needs to investigate them.
This also keeps source attribution clean. When the agent reads a docs page, we can track that file and turn it into a public docs URL to include in the final draft.
The result is a narrower, more reliable use of an LLM: not "answer from memory," but "search until you have enough evidence, then stop."
Why we kept the docs local
One of the more pragmatic decisions in the project was to make the documentation corpus a git submodule inside the repo.
That gave us a few immediate advantages.
First, the search tools operate on local files, so the agent can do fast, repeated searches without hitting a remote docs API or relying on a separate indexing pipeline.
Second, the docs search is easy to constrain. The tools are scoped to the docs directory, which means the bot cannot wander across unrelated parts of the codebase while it is supposed to be researching product behavior.
Third, it makes attribution easy. The same path the agent reads from can be translated into the public docs URL that support engineers can verify.
This is a small architectural choice, but it captures the overall design philosophy of the bot well: use the simplest mechanism that gives the model good context and gives humans clear provenance.
Building memory for support
The live investigation flow only works well if the historical memory is fresh.
So we built a second event-driven pipeline that ingests support history into a vector index.
That pipeline is split into three Inngest functions.
1. Ticket orchestrator
The orchestrator paginates through Plain threads, extracts the first customer message from each ticket, and emits batches for downstream processing.
This function is mostly about I/O and pacing. It handles pagination, batching, and the small amount of rate-limiting needed to avoid hammering the support API.
2. Embedding processor
The embedding processor consumes those ticket batches and generates embeddings in manageable chunks.
This separation is useful for two reasons.
First, embedding generation is the expensive part, so it deserves its own stage.
Second, once the work is evented and batched, we can scale it independently from the Plain export step.
3. Database writer
The final stage writes the embedded tickets into PostgreSQL with upsert semantics keyed on the thread ID.
That keeps ingestion idempotent. If we reprocess the same ticket later, we update the record instead of creating duplicates.
The table itself is intentionally small.
We store the thread ID, title, extracted ticket content, embedding, and timestamps. We do not try to duplicate the entire support platform inside our own database.
When the live investigation flow needs more detail, it can go back to Plain and pull the full thread conversation on demand.
That tradeoff keeps the vector store lean while still allowing deep retrieval when a specific ticket looks relevant.
Why Inngest was a good fit
This project is a nice example of where event-driven orchestration is better than a single request handler.
There are multiple external systems involved.
- Plain for live ticket data and note creation
- Anthropic for generation
- OpenAI for embeddings
- PostgreSQL with
pgvectorfor retrieval - A local documentation corpus for file-based search
There are also multiple different execution shapes.
- A user-facing investigation flow that should feel direct
- A backfill and refresh pipeline that should handle batching cleanly
- Several steps that are I/O bound and retryable
Putting this into Inngest let us treat the whole thing as a workflow instead of a pile of nested async calls.
The support path becomes a sequence of named steps.
The indexing path becomes a small pipeline of events with batching at the places where batching actually helps.
That means the architecture stays easy to reason about even though the system is pulling context from several different places.
Guardrails mattered more than cleverness
The parts of the system we trust most are not the ones that sound the most "AI."
They are the guardrails.
The bot is intentionally constrained in a few ways.
Drafts only
The workflow produces an internal note, not a customer-visible reply.
That keeps a human in the loop and makes the bot useful earlier. A support engineer does not need to trust it enough to send automatically. They only need it to save them time on the initial investigation.
Bounded research
The docs agent has explicit tools, explicit stopping conditions, and loop-detection logic.
That matters. The difference between a useful research agent and an expensive one is often whether it knows when to stop.
Source visibility
The final draft includes the evidence that produced it: links to similar tickets, links to documentation pages, and the originating event.
That changes the review experience completely.
Instead of reading a paragraph and wondering whether it is right, the reviewer can inspect where it came from.
Narrow outputs
The bot is not trying to resolve incidents, file PRs, or take product actions. It is doing one job: an initial support investigation.
That narrow scope makes the rest of the design much simpler.
What we learned
Three things stood out while building this.
Retrieval beats recall
Even when the model is strong, the system gets better when the model is asked to retrieve context instead of inventing it.
The most helpful drafts usually come from combining documentation with precedent.
Past tickets are an underrated knowledge base
Support organizations already contain a large amount of useful product knowledge, but it is usually trapped in long threads and hard to search well.
Once we indexed that history semantically, a lot of repetitive support work started looking much more structured.
Small, explicit systems are easier to trust
This bot is not impressive because it is broad.
It is useful because it is specific.
Every major piece of behavior is legible:
- where context comes from
- how historical memory is built
- how docs are searched
- where the final draft gets posted
That is what made it feel practical rather than experimental.
What this system is not
It is not a general-purpose agent platform.
It is not a replacement for support engineers.
It is not an auto-responder that should talk to customers without review.
It is a focused investigation layer that makes the first pass on a ticket faster and better grounded.
That is enough.
For support workflows, "enough" is often exactly what you want. The goal is not to create a magical autonomous worker. The goal is to reduce repetitive research, preserve accuracy, and give the human reviewer a better starting point.
What's next
The next obvious extension is run diagnosis.
Today, the bot investigates tickets using the live thread, similar historical tickets, and documentation. But a big part of real support work is confirming what actually happened in production: inspecting a function run, looking at traces, and, when needed, digging into the ClickHouse data behind retries, failures, and stuck runs.
That would add a fourth source of truth to the system: runtime evidence. Not just what the docs say and what happened before, but what happened in this specific run.
The shape we would build again
If we were building this from scratch again, we would keep the same core shape.
- Use events to kick off investigation.
- Keep the research paths separate: live thread, docs, and historical memory.
- Store a compact semantic index, then fetch full context only when needed.
- Keep the output reviewable and source-backed.
That combination ended up being much more valuable than trying to make the model feel universally smart.
The best support automation we found was not "answer faster."
It was "investigate first."


