You're part of a small team building a resume parser for a large job-matching platform. The goal is simple: parse resumes, score candidates, and notify them of relevant job listings.
Your team picks Kafka for its speed, low latency, and strong community support. But what starts as a straightforward pipeline: parse → score → notify, quickly spirals into a tangle of retries, deduplication logic, and Redis patches.
Suddenly, you're not shipping features, you're maintaining infrastructure.
While building the resume parser with Kafka, your team has three key goals:
- Prioritize newly submitted resumes over background jobs
- Avoid reprocessing unchanged resumes to save compute costs
- Rate limit requests to a third-party parsing API to avoid throttling or surprise bills
Simple requirements… in theory.
To implement them, you set up Kafka and Redis: using Redis to cache recent resume hashes for deduplication, storing timestamps to rate limit API calls per user, and tracking submission IDs to simulate prioritization by filtering consumer logic.
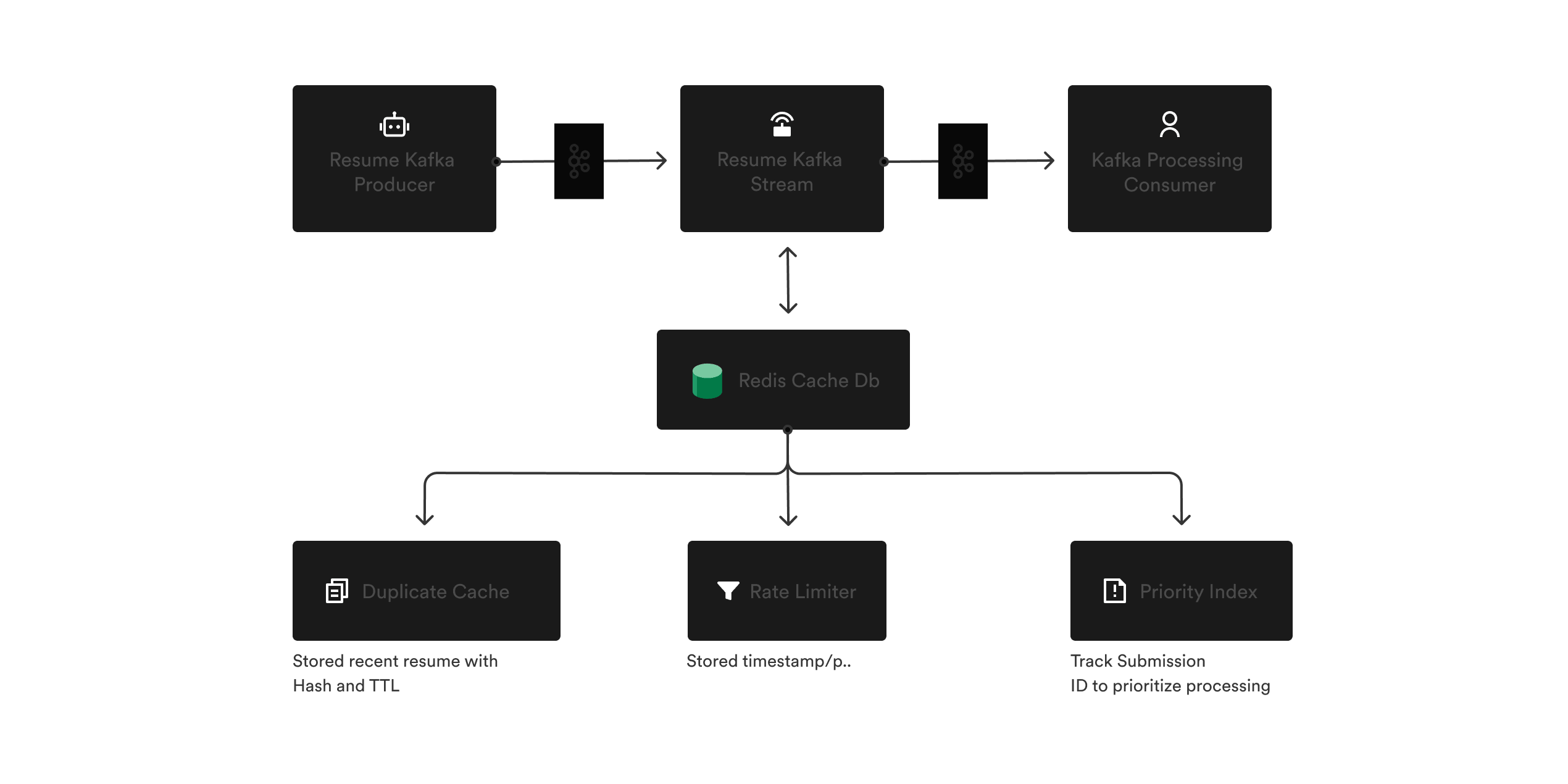
At first, it seems manageable. But soon your team realizes you're spending more time stitching Kafka and Redis together, and end up writing custom coordination logic (e.g., deduplicating/rescheduling messages, rate limiting per user), then fighting race conditions when multiple consumers grab similar jobs at once, and finally managing retries, visibility, and weird edge cases by hand, building delay/retry topics, dead-letter queues, and lots of logging just to keep the pipeline stable.
Coordination logic (Redis dedupe + per-user rate limit)
// ioredis ^5, kafkajs ^2import Redis from "ioredis";const redis = new Redis(process.env.REDIS_URL);// Deduplicate: only process a resume hash once per 10 minutesexport async function shouldProcess({ resumeUrl, version }) {const key = `dedupe:${Buffer.from(`${resumeUrl}:${version}`).toString("base64url")}`;// NX = set only if not exists; EX = TTL secondsreturn Boolean(await redis.set(key, "1", "EX", 600, "NX"));}// Rate limit: allow N calls per user per windowexport async function underLimit(userId, limit = 3, windowSec = 3600) {const key = `ratelimit:user:${userId}`;const n = await redis.incr(key);if (n === 1) await redis.expire(key, windowSec);return n <= limit;}
Prevent race conditions (simple distributed lock)
// Distributed locking pattern with Redisimport crypto from "node:crypto";import Redis from "ioredis";const redis = new Redis(process.env.REDIS_URL);// Acquire a lock, run fn, then safely releaseexport async function withLock(lockKey, ttlMs, fn) {const token = crypto.randomUUID();const ok = await redis.set(lockKey, token, "PX", ttlMs, "NX");if (!ok) return { acquired: false };try {const result = await fn();return { acquired: true, result };} finally {// Release only if we still own the lock (Lua CAS)const lua = `if redis.call("get", KEYS[1]) == ARGV[1] thenreturn redis.call("del", KEYS[1])else return 0 end`;await redis.eval(lua, 1, lockKey, token);}}// Usage// const { acquired } = await withLock(`lock:submission:${id}`, 30000, () => doWork());
Manual retries, backoff, DLQ (KafkaJS)
// Initialize Kafka client and consumersimport { Kafka } from "kafkajs";const kafka = new Kafka({ clientId: "svc", brokers: process.env.KAFKA_BROKERS.split(",") });const producer = kafka.producer();const consumer = kafka.consumer({ groupId: "resumes-v1" });// Retry configurationconst MAX_RETRIES = 5;const nextBackoffMs = (a) => Math.min(60_000, Math.round((2 ** a) * 500 * (0.5 + Math.random())));// Send message to retry topic with exponential backoffasync function sendToRetry(msg, attempt) {await producer.send({topic: "resumes.retry",messages: [{key: msg.key?.toString(),value: msg.value?.toString(),headers: { ...msg.headers, attempt: String(attempt), availableAt: String(Date.now() + nextBackoffMs(attempt)) },}],});}// Send message to dead-letter queue when max retries reachedasync function sendToDLQ(msg, reason) {await producer.send({topic: "resumes.dlq",messages: [{ key: msg.key?.toString(), value: msg.value?.toString(), headers: { ...msg.headers, error: String(reason).slice(0, 200) } }],});}// Delay worker to requeue when availableAt is reachedasync function runDelayWorker() {const retryConsumer = kafka.consumer({ groupId: "resumes-delay" });await Promise.all([producer.connect(), retryConsumer.connect()]);await retryConsumer.subscribe({ topic: "resumes.retry" });await retryConsumer.run({eachMessage: async ({ message }) => {const due = Number(message.headers?.availableAt || "0");const wait = Math.max(0, due - Date.now());if (wait) await new Promise(r => setTimeout(r, Math.min(wait, 30_000)));await producer.send({ topic: "resumes", messages: [{ key: message.key, value: message.value, headers: message.headers }] });},});}// Main consumer with visibility + retry handlingasync function runConsumer(processFn) {await Promise.all([producer.connect(), consumer.connect()]);await consumer.subscribe({ topic: "resumes" });await consumer.run({eachMessage: async ({ message }) => {const attempt = Number((message.headers?.attempt || "0").toString());try {await processFn(JSON.parse(message.value.toString()), message);} catch (err) {if (attempt + 1 >= MAX_RETRIES) await sendToDLQ(message, err.message || "unknown");else await sendToRetry(message, attempt + 1);}},});}
Now you're explaining to the PM why a 5-minute delay” would take a sprint to implement
The infrastructure you hoped would speed you up is now slowing you down.
Growing frustrated with the complexity, one of your engineers starts looking for a simpler solution. After some research, they stumble across Inngest's Flow Control .
Flow Control in Inngest lets you manage how and when your functions run. You can control things like resource usage (CPU, concurrency), event execution order, how functions behave in a queue, and how often they run per event.
The team realizes that everything the team was trying to build manually, rate limiting, deduplication, retries, and prioritization, is already handled natively within Inngest.
So instead of stitching together Kafka consumers and Redis keys, they can use declarative primitives like:
Debounce to avoid duplicate processing
Prevent duplicate resumes from being parsed within a short window:
export default inngest.createFunction({id: "handle-webhook",debounce: {key: "event.data.resume_id",period: "5m",timeout: "10m",},},{ event: "user/resume.updated" },async ({ event, step }) => {// This function will only be scheduled 5 minutes after events are no longer received with the same// `event.data.resume_id` field.//// `event` will be the last event in the series received.});
Throttle to control API usage
Limit how frequently a user can trigger expensive operations:
export default inngest.createFunction({id: "unique-function-id",throttle: {limit: 1,period: "5s",burst: 2,key: "event.data.user_id",},},{ event: "jobs/job_posts" },async ({ event, step }) => {// This function will only allow 1 request every 5 seconds per user_id// with a burst allowance of 2 requests});
Built-in durability, retries, and observability
No need to write retry logic or track state, Inngest handles all of that automatically. If a step fails, it retries with backoff. If a user uploads multiple resumes, you can cancel previous runs. And you get full visibility into every workflow with step-by-step logs.
With Flow Control , what once required a distributed system of Kafka, Redis, and coordination code becomes a simple, maintainable function that just works, and scales.
Now the team no longer has to worry about patching Redis logic, writing custom retry handlers, or managing Kafka infrastructure. They can finally focus on what actually matters: building a great product.
The team is shipping faster. Bugs related to duplicate resume processing have disappeared. API usage has dropped thanks to built-in throttling. Product managers can now suggest changes or new features without it turning into a full sprint of Kafka reconfigurations.
Kafka is powerful, no doubt, but for most teams, especially those building product workflows, it's too much. You end up writing glue code, managing extra infrastructure, and solving problems that have already been solved a hundred times.
Inngest's Flow Control gives you those same capabilities, without the overhead. You get retries, rate limiting, debouncing, throttling, prioritization, and more, all built-in, all configurable, and all production-ready.
So if you're spending more time managing queues than delivering features, maybe it's time to ask a better question:
What if your event-driven architecture didn't need to be this hard?
What's new
Singleton Functions: Exclusive execution control (June 2025)
Building on Inngest's Flow Control capabilities, Singleton Functions provide another way to avoid the complexity of Kafka and Redis coordination. Where you might have used distributed locks or complex deduplication logic with Kafka, Singleton Functions ensure exclusive execution—a powerful addition to rate limiting, throttling, and debouncing:
const latestDataSync = inngest.createFunction({id: "latest-data-sync",singleton: {key: "event.data.user_id",mode: "cancel", // or "skip"}},{ event: "data-sync.start" },async ({ event }) => {// Any existing run for this user will be cancelledconst payload = await fetchLatestUserData(event.data.user_id);await applyRealTimeUpdates(payload);});
Two modes for different use cases:
skipmode: Discard new events while a run is in progresscancelmode: Cancel existing runs and start fresh with the latest data
Perfect for scenarios where only the most recent execution matters:
- Live dashboards that need latest data
- Real-time sync operations
- Deduplication of rapid user actions
- Ensuring only one payment processes per order
Unlike rate limiting (which controls frequency) or debouncing (which delays execution), Singleton Functions ensure mutual exclusion—only one run per key executes at a time.