
Key Takeaways
- Durable execution, a programming model that guarantees code completion despite failures, has crossed into the early majority in 2025 with new offerings from AWS, Cloudflare, and Vercel, driven primarily by AI Agent infrastructure needs.
- AI Agents introduce multiple points of failure (orchestration, probabilistic LLM behavior, tool calling, human-in-the-loop) that traditional retry logic cannot handle; durable execution provides automatic state persistence, automatic retries, and workflow resumption that make agents production-ready.
- Human-in-the-loop (HITL) patterns, essential for AI Agent safety and oversight, map directly to durable execution's suspend/resume primitives, enabling workflows that can pause for hours or days awaiting approval without losing state.
- Tool calling reliability depends on durable execution's ability to checkpoint between calls, implement backoff strategies, and maintain execution context across transient failures from external APIs.
- The next evolution of durable execution focuses on low-latency patterns that support interactive, user-facing AI agents, moving beyond background "ambient agents" to real-time conversational experiences.
Introduction
Haven't heard the phrase "durable execution?" In short, it just means ensuring code executes correctly, no matter what. Durable execution platforms use APIs to shift the burden of infrastructure work from back-end and systems engineers to a platform that guarantees the execution of critical logic across multiple failures or over a long period of time.
While the term might feel new, the architecture has existed for a few years now—Temporal popularized it as an altenrative to hand-rolled systems, and Azure Durable Functions and Inngest brought it to serverless. In late 2025, however, durable execution crossed the chasm into the early majority. AWS released Durable Functions, Cloudflare shipped Workflows in GA, and Vercel launched its Workflow DevKit. This timing is not coincidental. The common thread driving adoption is AI.
AI agents tackled most of their early challenges (hallucinations, safety) with the introduction of orchestration patterns, human-in-the-loop (HITL), tool calling, and reasoning. These architectural components represent significant progress. They also introduce multiple points of failure that durable execution is uniquely positioned to address.
These components of AI Agents' accuracy and reliability are the key trend of 2026: AI Agent Harnessing.
The Challenges of Bringing AI Agents to Production
Traditional software is deterministic. Given the same inputs, you expect the same outputs. When something fails, you can often retry the entire operation without side effects.
AI agents break these assumptions in fundamental ways.
First, agents are probabilistic. The same prompt can produce different responses across calls. A retry might not produce equivalent results, making idempotency more complex than a simple cache lookup.
Second, agents are compositional. A single user request might trigger a planning phase, multiple tool calls, memory retrieval, and a synthesis step. Each component can fail independently, and the failure modes compound. If you have five steps with 99% reliability each, your overall success rate drops to 95%. With ten steps, you're at 90%. Real-world agents often involve dozens of operations.
Third, agents are stateful. The context window accumulates information across the workflow. Losing that state mid-execution means losing the reasoning chain, the intermediate results, and the plan the agent was following.
Consider a Lead Scouting Agent tasked with finding qualified Sales leads. The workflow might look like this:
- Plan the research approach based on user requirements
- Search the web for companies
- Scrape content from each website by navigating it
- Extract structured data using an LLM
- Generate a summary report
Each step can fail. The search API might rate-limit. Scraping might fail. The LLM might hallucinate data that doesn't exist or time out.
Traditional approaches to this problem fall short:
- Simple retries help with transient failures but don't preserve state across function restarts. If your serverless function times out, you lose everything.
- Manual checkpointing requires developers to explicitly save state after each operation, handle partial failures, and implement recovery logic. This works but adds significant complexity to every workflow.
- Queue-based architectures decompose the workflow into separate jobs, but coordinating state across those jobs becomes its own infrastructure project. You end up building half of a durable execution engine yourself.
The fundamental issue is that AI agent workflows are long-running by nature. They can take minutes or hours to complete. They need to survive infrastructure failures, deployment restarts, and external service outages. They need exactly-once semantics for operations that cost money or have side effects.
While some might argue that the above technical requirements can be met with traditional queues or home-made solutions, the market reality is that the best AI Agents are quickly brought to market using durable execution to tackle these architectural challenges.
Durable Execution is the AI Agent Harness
Durable execution platforms share a core abstraction: code that automatically persists its state at defined checkpoints and can resume from those checkpoints after any failure. The developer writes what looks like normal sequential code, but durable execution handles the complexity of making it fault-tolerant:
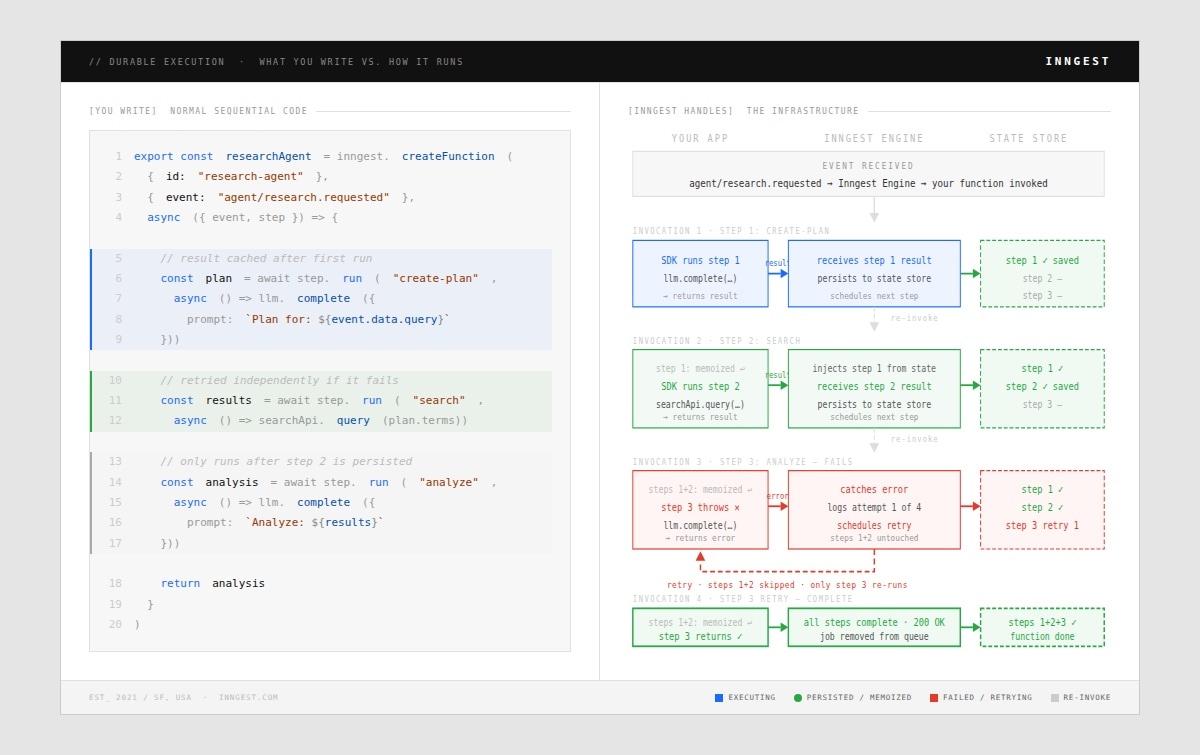
Let's examine how this maps to the specific challenges of AI agent architectures.
Agentic Orchestration and State Management
Modern AI agents rely on orchestration patterns to coordinate multiple components. Whether you're using LangChain's chains, Inngest's steps, or building custom workflows, you're composing operations that need to execute reliably.
Durable execution provides two critical capabilities here: automatic state persistence and exactly-once execution semantics.
With automatic state persistence, the durable execution engine captures the result of each step. If the workflow restarts, it replays from the last successful checkpoint rather than re-executing everything. This is especially valuable for LLM calls, where re-execution means re-paying for tokens.
Consider this pattern using a durable workflow:
async function researchWorkflow({ event, step }) {// Step 1: Plan the researchconst plan = await step.run("create-plan", async () => {return await llm.complete({prompt: `Create a research plan for: ${event.data.query}`});});// Step 2: Execute searches (this won't re-run if we restart here)const searchResults = await step.run("search", async () => {return await searchApi.query(plan.searchTerms);});// Step 3: Analyze resultsconst analysis = await step.run("analyze", async () => {return await llm.complete({prompt: `Analyze these results: ${JSON.stringify(searchResults)}`});});return analysis;}
If this workflow fails during the analysis step, it resumes from that point. The planning and search steps don't re-execute. Their results are retrieved from the durable state store.
This has direct cost implications. LLM calls are expensive. Re-running them on every retry doubles or triples your inference costs. Durable execution's caching behavior means you pay for each LLM call exactly once.
The pattern also provides flexibility that fixed DAG-based workflows can't match. Agents need to make dynamic decisions about what to do next based on intermediate results. Code-based durable workflows let you express arbitrary control flow with conditionals, loops, and dynamic branching while maintaining durability guarantees.
Human-in-the-Loop as a First-Class Primitive
Human-in-the-loop (HITL) patterns are essential for production AI agents. Users need to approve high-stakes actions, correct mistakes, and provide guidance when the agent is uncertain.
The challenge is that HITL introduces unbounded delays. A human might respond in seconds, hours, or days. Traditional request-response architectures can't handle workflows that pause indefinitely.
Durable execution solves this with suspend and resume primitives. The workflow pauses at a defined point, persists its complete state, and waits for an external signal. When the signal arrives, the workflow resumes exactly where it left off.
Here's what this looks like in practice:
async function contentPublishingWorkflow({ event, step }) {// Generate contentconst draft = await step.run("generate-draft", async () => {return await llm.complete({prompt: `Write an article about: ${event.data.topic}`});});// Wait for human approval (can take hours or days)const approval = await step.waitForEvent("approval-received", {event: "content/approved",match: "data.draftId",timeout: "7d"});if (!approval.approved) {// Human requested changes, regenerate with feedbackconst revisedDraft = await step.run("revise-draft", async () => {return await llm.complete({prompt: `Revise this draft based on feedback: ${approval.feedback}\n\nOriginal: ${draft}`});});// Wait for approval againawait step.waitForEvent("revision-approved", {event: "content/approved",match: "data.draftId",timeout: "7d"});}// Publish the approved contentawait step.run("publish", async () => {return await cms.publish(draft);});}
The waitForEvent call suspends the workflow entirely. No compute resources are consumed while waiting. The workflow state persists in the durable store, surviving deployments, scaling events, and infrastructure changes.
When the approval event arrives (via webhook, API call, or UI action), the platform routes it to the correct workflow instance and resumes execution. The developer doesn't need to build correlation logic, event routing, or state recovery. The durable execution engine handles it.
Tool Calling Reliability
Tool calling is where AI agents interact with the real world. They query databases, call APIs, send emails, and create records. These operations are exactly where reliability matters most.
External APIs fail in varied ways: rate limits, timeouts, network errors, authentication expiration, and server errors. A production agent needs to handle all of these gracefully without losing progress.
Durable execution provides automatic retries with configurable backoff strategies. Each tool call becomes a durable step that will retry on failure until it succeeds or exhausts its retry budget:
async function dataEnrichmentWorkflow({ event, step }) {const contacts = event.data.contacts;const enrichedContacts = [];for (const contact of contacts) {// Each enrichment call retries independentlyconst enriched = await step.run(`enrich-${contact.id}`, async () => {return await enrichmentApi.lookup(contact.email);}, {retries: 5,backoff: {type: "exponential",initial: "1s",max: "5m"}});enrichedContacts.push({ ...contact, ...enriched });}// Store resultsawait step.run("store-results", async () => {return await database.bulkInsert(enrichedContacts);});}
If the enrichment API rate-limits on the 15th contact, the workflow pauses, waits according to the backoff schedule, and retries. The first 14 enrichments don't re-run because their results are already persisted.
This pattern is especially powerful for agents that make many tool calls. A coding agent might read files, run tests, query documentation, and execute commands dozens of times per task. Each operation needs independent retry handling, and the overall workflow needs to survive any individual failure.
Durable execution also simplifies idempotency. Because step results are cached, you can safely retry the entire workflow without worrying about duplicate side effects. The durable execution engine ensures each step executes exactly once, even if the workflow function itself runs multiple times.
The Path Forward: Low-Latency Durable AI Agents
The patterns described above work well for background agents that operate asynchronously. A user submits a request, the agent works, and results appear later. These "ambient agents" handle research, analysis, and processing tasks where latency is measured in minutes.
But user expectations are evolving. With reasoning models becoming more trustworthy and agents demonstrating real capabilities, users want to interact with agents directly. They want conversational experiences where the agent responds in real-time while maintaining the reliability of durable execution.
This creates a tension. Traditional durable execution platforms optimize for throughput and reliability, not latency. Persisting state after every step adds overhead. Recovery mechanisms assume failures are rare, not that users are waiting milliseconds for responses.
The next evolution of durable execution addresses this with several approaches:
Durable endpoints treat HTTP handlers themselves as durable workflows. The request processing runs in a durable context, allowing tools that suspend and resume without closing the connection. This enables streaming responses that maintain durability guarantees.
Optimistic execution runs steps immediately while persisting state asynchronously. In the common case where nothing fails, latency approaches non-durable code. When failures occur, the system recovers from the last persisted checkpoint.
Edge-based execution moves durable workflows closer to users, reducing network latency while maintaining central coordination for long-running operations.
These capabilities are emerging in durable execution engines now. Cloudflare Workflows runs at the edge. Inngest is bringing durability to API endpoints. Specialized AI platforms are building durable primitives directly into their inference SDKs.
The implication for agent builders: architecture decisions you make today should account for this shift. Design your agents with clear boundaries between interactive components (that need low latency) and background components (that need high reliability). Use durable execution for both, but expect the interface between them to evolve as platforms mature.


