
A lot has been written about Context Engineering theory and its principles, with few examples. At Inngest, we are fortunate to experience context engineering in practice through our exchanges with our community and customers, which include leading AI products such as Outtake, Replit, and 11x.
This blog post serves as a practical reference for Context Engineering using Inngest, covering how we built an AI Research Assistant by providing it with a rich, reliable context engineering pipeline to answer questions such as “What are the latest advances in transformer architectures?”:
You will learn:
- What is Context Engineering, and why does it matter
- How to build a rich and reliable data source pipeline using Flow Control
- The importance of choosing models based on their strengths
- How to orchestrate retrieval and augmentation workflows to build a rich context
Let's get started!
What is Context Engineering, and why does it matter
The rise of Context Engineering originates from the observation, by both practitioners and researchers, that AI Agents' accuracy is directly linked to the quality of their context.
As LLMs' reasoning capabilities have improved (and continue to do so), the need to provide fine-tuned prompts and extensive context is diminishing. Instead, we give the LLMs the richest and most accurate context possible, which includes: query-related data (ex, user data), cleaned, augmented, and JSON-formatted data, memory (short and long term), as well as valuable tools:
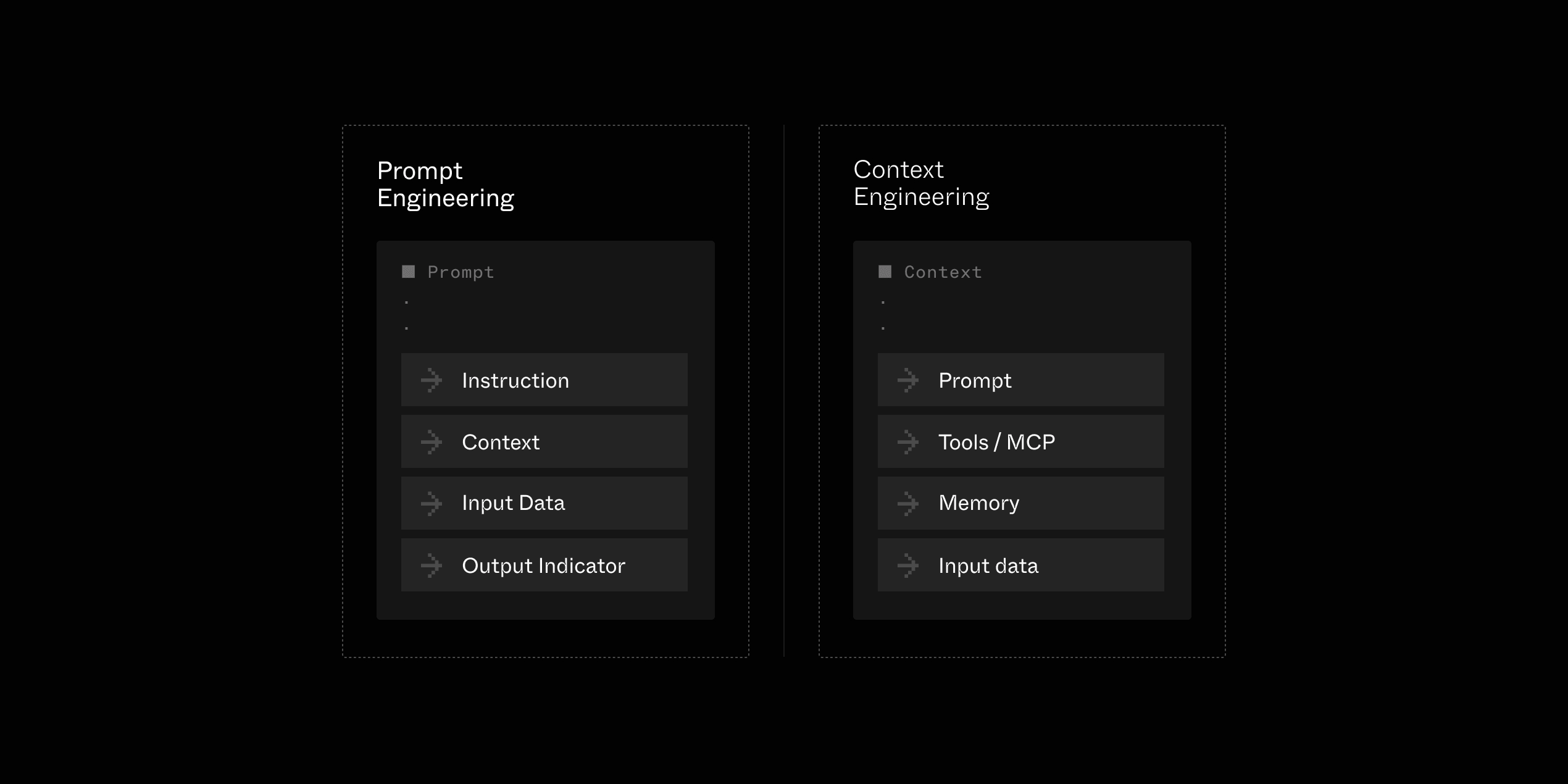
To learn more about Context Engineering, dive into our Five Critical Lessons for Context Engineering and Context Engineering is just software engineering for LLMs articles.
The components of a reliable and accurate AI Research Assistant
Enough with the theory, let's see how to put Context Engineering in practice by looking at our AI Research Assistant example.
Our AI Research Assistant aims to provide the best answer to general and domain-specific questions:
- “What are the latest advances in transformer architectures?” (AI research knowledge)
- “Explain retrieval-augmented generation” (AI research knowledge)
- “How does rate limiting work in distributed systems?” (General knowledge)
- “What are the latest open-source trends?” (GitHub knowledge)
Such requirements raise the following question:
- Which AI Agent architecture should we use? (”Orchestrator-workers”, “Evaluator-optimizer”, “Agents”)
- How should the context be built? With which data sources and models?
Let's answer them.
Which AI Agent architecture should we use?
AI Agents (as end products) can be built in numerous ways, from chat-based UIs to CLIs, and from RAG workflows to agent loops with memory and tools.
This raises the question of “Context pushing” vs. “Context pulling”: should we provide the context to the LLM or let the LLM ask for context via tool calling?
A good rule of thumb for choosing between “Context pushing” and “Context pulling” depends on the size of the data to explore and the level of autonomy.
For example, a Coding Agent helping evolve an application with thousands of files will require reasoning capabilities to dynamically “pull the context” it needs (by exploring the codebase). An entire codebase cannot reasonably fit in a context window without degrading the LLM accuracy.
Our AI Research Agent has a simple (yet challenging) mission: answer a question within a given domain.
Answering questions such as “Explain retrieval-augmented generation” can be achieved with a given set of data sources and some reasoning to compare them.
For this reason, our AI Research Agent is architected using the “Orchestrator-workers” pattern, where the context is retrieved and augmented before being passed to a final LLM call (“the Agent”).
What makes an AI Agent?
An AI Agent differs from other products or features by its chat-based or dynamically evolving nature.
An AI Agent can be powered by an agentic workflow (a workflow with some dynamic steps) or by an agent loop combined with memory and tools that provide reasoning capabilities.
Let's now take a closer look at our context pipeline.
How should the context be built? With which data sources and models?
To answer the set of questions introduced above, our AI Research Assistant will receive a context composed of data retrieved from 4 high-quality data sources (ArXiv, GitHub, Web search via the SERP API, and uploaded PDFs), as well as the combination of 4 specialized Agents to avoid biases:
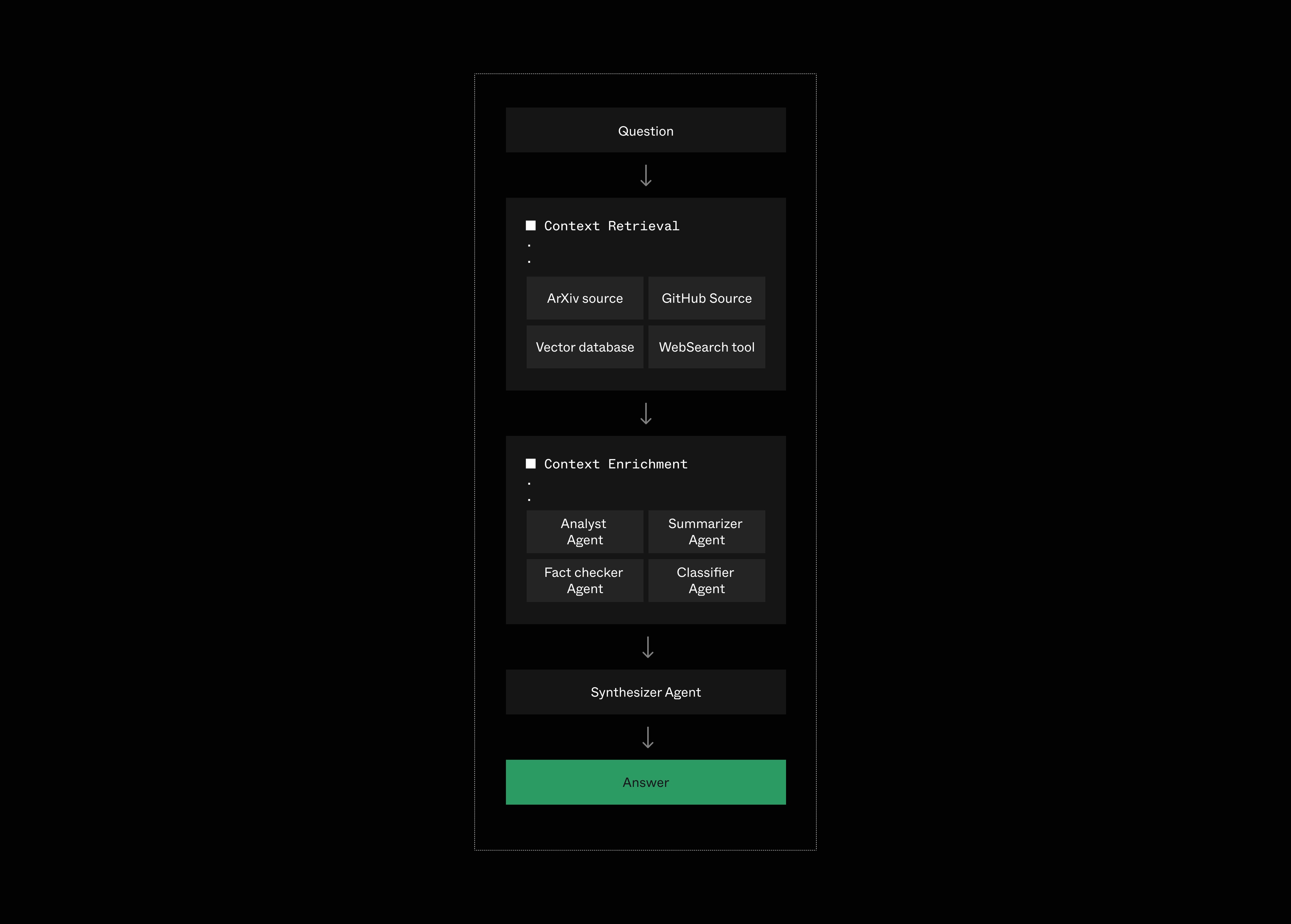
Let's now have a closer look at the layers of our context pipeline.
Retrieving a diverse and large amount of data reliably
An essential factor in context quality resides in the choice of high-quality data sources.
For a personal AI Assistant, retrieving data deeply integrated with the user's tools, like Google Calendar or meeting recordings, is crucial (see Day AI's architecture).
Our AI Research Assistant's context is provided by high-quality data from ArXiv (for the latest research publications), GitHub (we are developers, right?), Web search via the SERP API (the WWW), and uploaded PDFs (for personal documents).
Retrieving data is the first challenge of context engineering, and it is a double-edged sword:
- On one side, the variety and quality of sources require work to match each data source's rate limit and reliability
- On the other side, retrieving the data should be a swift process, keeping the user in the loop, no matter how much data is required
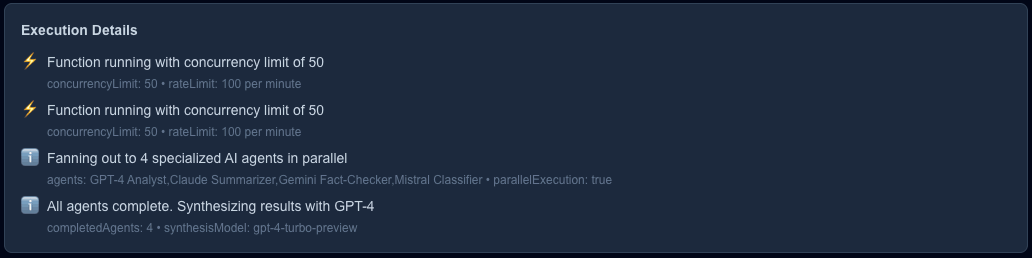
To cope with all these challenges, our AI Research Assistant retrieves the data from the four different data sources in parallel:
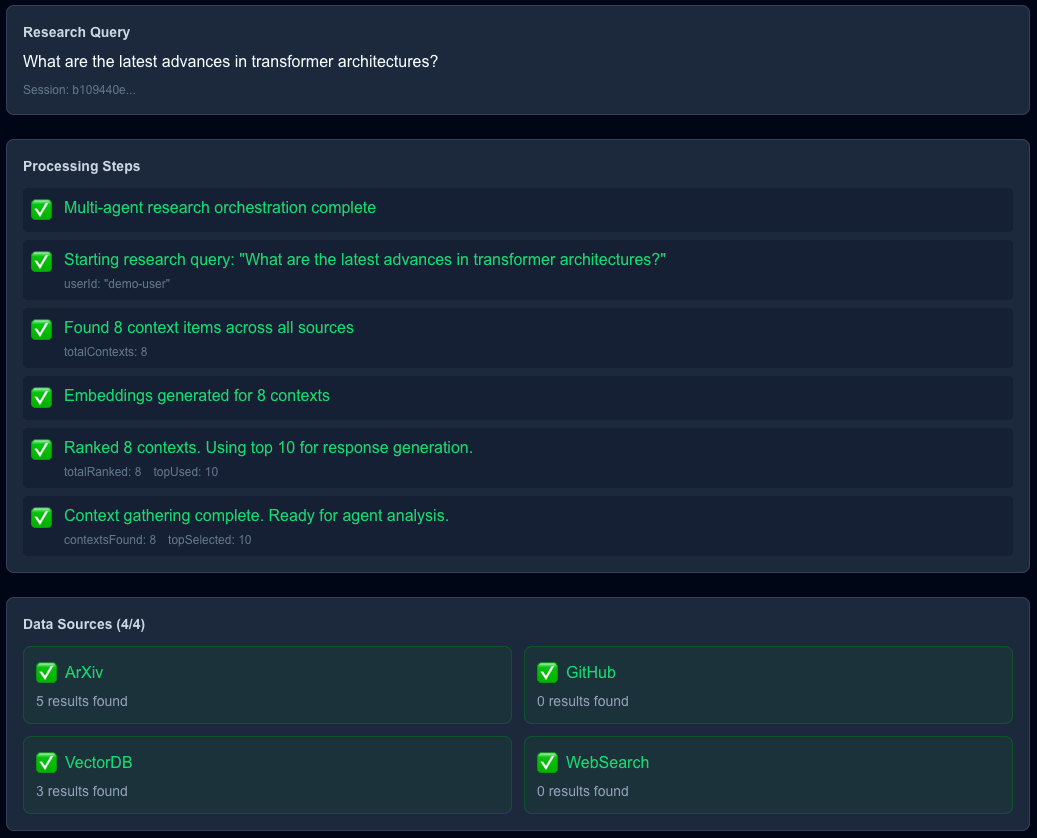
Quickly retrieving data from multiple external APIs is achieved with:
- Durable execution by creating Inngest workflows that automatically retry upon failures
- Rate Limit configuration to cope with 3rd party API usage limits (ex, ArXiv allows 1 request per second)
- Parallelized data fetching using Inngest steps
All of the above may seem like a lot of work, but it really is just a few lines of code:
export const gatherContext = inngest.createFunction({id: "gather-research-context",name: "Gather Research Context",// Global rate limitingconcurrency: { limit: 50 },rateLimit: { limit: 100, period: "1m" },},{ event: "research/query.submitted" },async ({ event, step, publish }) => {// ...// each step get retried upon failureconst { contexts, results } = await step.run("fetch-all-sources",async () => {console.log(`Fetching contexts for query: "${query}"`);// we retrieve data in parallel across many sourcesconst results = await Promise.allSettled([fetchArxiv(query),fetchGithub(query),fetchVectorDB(query),fetchWebSearch(query),]);// ...})// ...})
All the retrieved data is then transformed into embeddings and ranked against the search query for relevance.
The top 10 data items (“contexts”) are then forwarded to the next step in our context pipeline: context augmentation using an LLM.
Compress contexts by combining multiple specialized models
As mentioned earlier in “What is Context Engineering?”, feeding all the top 10 retrieved contexts (webpages, PDFs, and such) directly to a single LLM call would produce poor results as LLMs' accuracy tends to diminish with the provided context size.
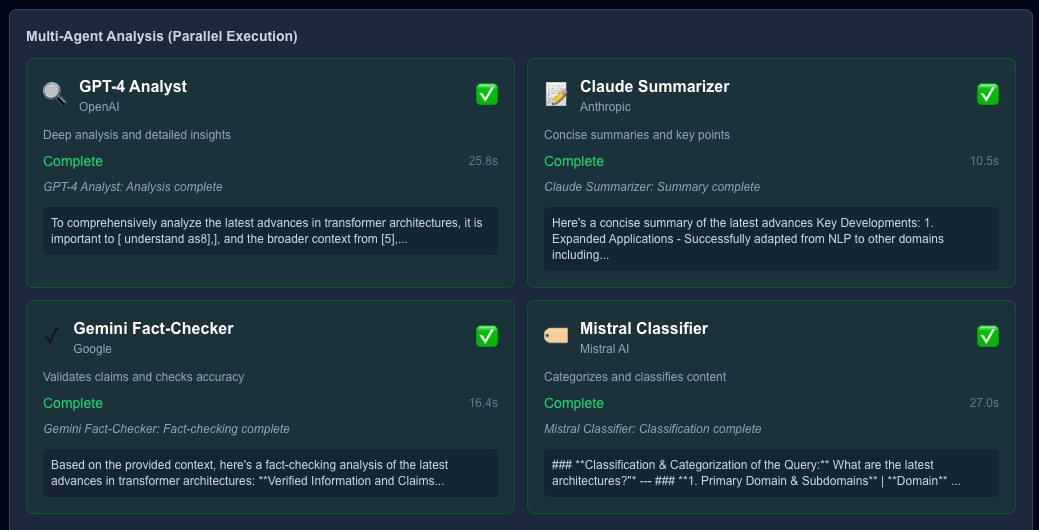
To enable our AI Research Assistant to provide the most accurate and unbiased answer, our top 10 retrieved contexts are forwarded to 4 specialized models, again, in parallel:
- The GPT-4 Analyst
- The Claude Summarizer
- The Gemini Fact-Checker
- The Mistral Classifier
This “divide and conquer” approach is an efficient context-engineering pattern that “compress” the context into smaller ones that are easier to reason about.
In addition to producing 4 smaller contexts, we leverage each model's strengths: Mistral Classifier for categorizing retrieved contexts and Gemini Flash for quick fact-checking, and so on.
Zooming out, this context-augmenting phase is architected following Anthropic's “Orchestrator-workers” pattern:
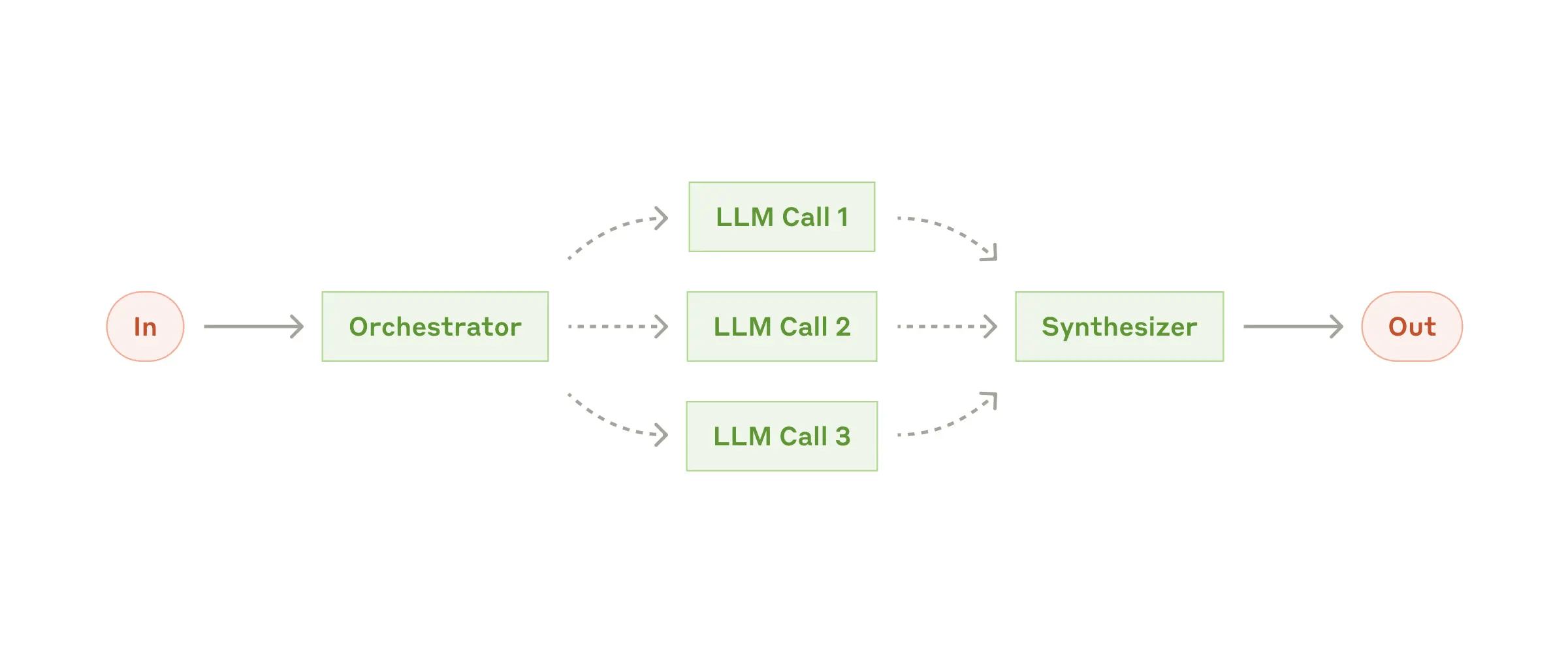
Learn more about the Orchestrator-workers pattern
We start an orchestrator workflow that runs the four specialized agents simultaneously and sends their compressed contexts to the synthesizer agent to generate the final answer:
Conclusion
This article demonstrated what context engineering looks like in practice. By constructing a context from high-quality data sources and refining it with multiple expert models, our AI Research Assistant, powered by Inngest workflows, quickly delivers rich and accurate answers.
Here are four rules of thumb to keep in mind when building context pipelines:
- Orchestration is the cornerstone of context pipelines: By leveraging Inngest's workflows, our context pipeline is resilient to external API failures, respects rate limits, and parallelizes work while enforcing concurrency constraints, all without any infrastructure effort.
- The quality of data sources is essential: how the context is provided depends on your use cases. Keep in mind that coding-related Agents tend to perform better with tools (”context-pulling”) while others might work just fine with predefined data sources.
- Context retrieval is a double-edged sword: Fetching external data should happen quickly, but external APIs' rate limits often constrain it. This double constraint can be overcome with patterns like Throttling and Parallelism.
- Augment and compress the contexts for better reasoning: While most LLMs' context windows keep increasing, their associated reasoning accuracy tends to diminish as context increases. Build your context pipeline to refine the context along the way and provide the shortest, most valuable context to your Agent (or the last LLM step).
The AI Research Assistant is fully open-source and available on GitHub for you to play with.


