
Stop guessing. Prove it in production.
Comparing code, tools, or models in a sandbox might tell you whether something works, but it won’t tell you what works better. Only Inngest lets you safely experiment on production traffic, using data already collected at execution.
The problem
Your eval tool can’t see business outcomes
How do you know if your agent works? LLM as a judge? User ratings? If you want to know which variant actually performed better, you used to have to stitch together data from multiple systems, implement human reviews, and build a layer of instrumentation on top.
REACTIVE
Today’s tools just tell you when your agent broke, not how it’s doing
OFFLINE
Testing in a sandbox against synthetic traffic is a fraction of reality
EXPENSIVE
Sampling your production runs because of cost means you lose valuable insights


A tighter feedback loop for agents
The data needed to make code durable is the same data needed to judge variant effectiveness—how long it takes to run, why it fails, how much it costs. Inngest captures all of this by default, without added instrumentation.
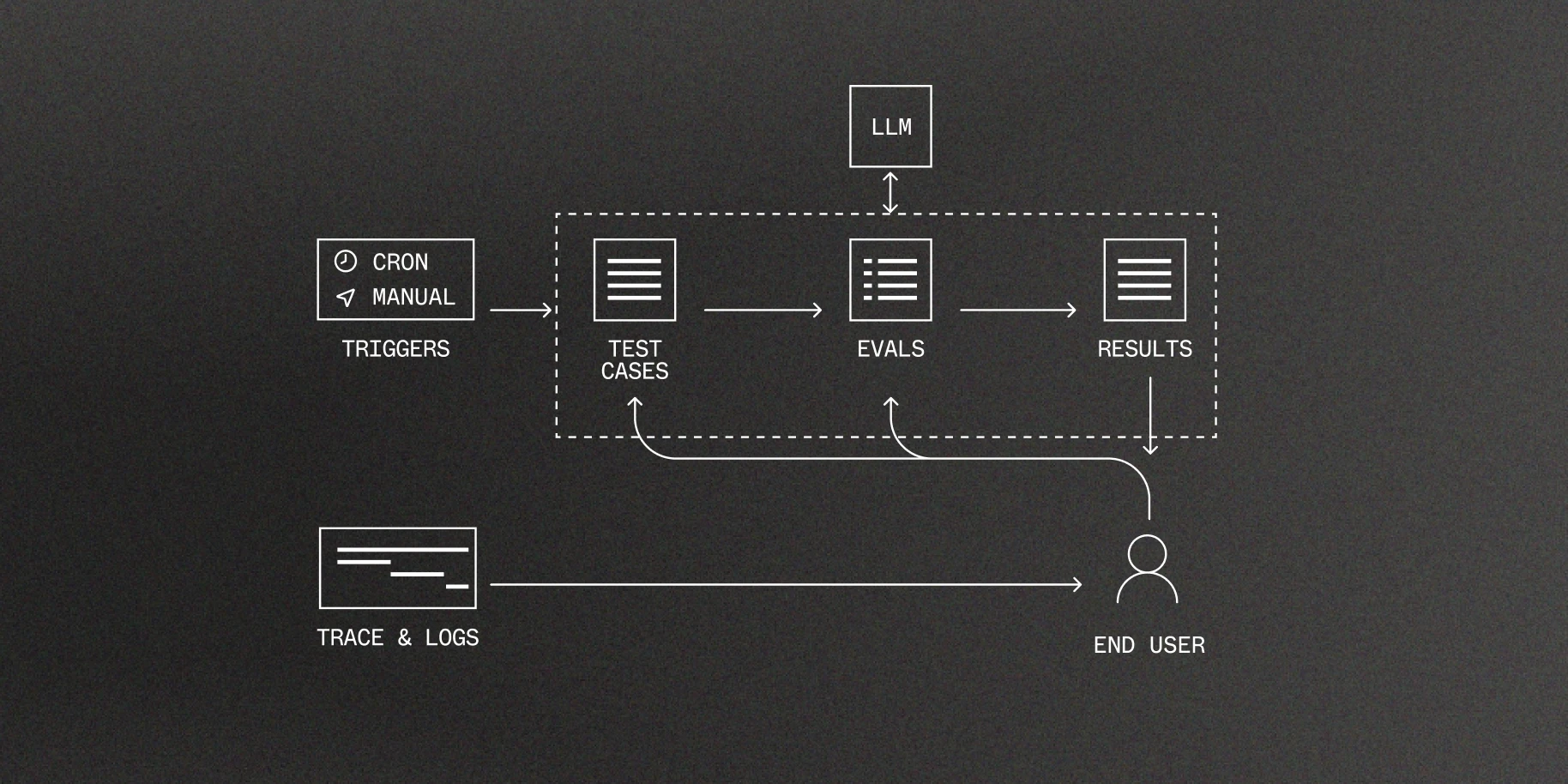

Score outcomes,not output
Score agents based on user and product signals, not just based on what one LLM says about another.
01
Score with step.score()
Scoring functions is just as easy as making them durable.
02
Track outcomes, not vibes
Track and score agents based off of what happens in your product using events.
03
Eval entire agent trajectories
Compare variants across multi-step workflows safely, with memoization so retries never switch mid-run.
Everything you need to safely test in production
Inngest makes your code durable and observable by default.
No added infrastructure or instrumentation.
Scoring
One shot was never enough. We let you use real production outcomes to eval variants.
Live Experiments
Test what works against live production traffic, or in a sandbox.
100% not 1%
Track outcomes across every run, without needing to sample.
Datasets
Generate datasets of good and bad runs for evals and offline replay.
Sessions
Group multiple agent loops or turns as a single conversation, thread, or however you choose.

Start scoring with Inngest
Outcome-based scoring, even days later
Wait to score based on a conversion event after the agent runs. No external pipeline, no trace ID threading.
A/B test prompts and models in production
Route live traffic between two variants and compare quality scores, cost, and latency across real users.
LLM-as-a-judge
Add this pattern to any experiment.
Cost management
Learn how to instrument and measure costs across agents.
Model fallback
Design retry-based fallbacks to other model providers during an outage.
FAQ
By business and product outcomes, not just model output. Did the shopper buy what the agent recommended? Did the user complete checkout? Those are the outcomes that matter, and they happen downstream of the variant that produced them—so judging on output alone misses them entirely.
Nope. LLM-as-a-judge is a technique that uses an LLM model to subjectively evaluate the results of another LLM (or agent) for certain criteria. LLM-as-a-judge can tell you the response read well—that the copy was fine, the user didn’t immediately bounce—but it can’t tell you whether the product outcome happened, because that outcome arrives later, as a separate event. Inngest provides flexible scoring APIs that let you evaluate against real-life user interactions, or implement your own custom LLM-as-a-judge if you want.
Online. You can run live A/B tests on real production traffic and compare variants on what users actually did, while it’s happening—not on a replayed sample after the fact.
Existing evals are mostly offline—curated test cases that only handle known-knowns. Inngest uses outcome-based signal to handle the unknowns—the wildcards—what really happens in prod. You’re not asking a model to judge itself; variants are measured against how your product actually behaved—events from real runs on real traffic—so the signal is the outcome, not an approximation of it.
No. Tools that score from outside the execution sample a fraction of traffic—often around 10%—because retaining and scoring everything is cost-prohibitive for them. For Inngest, the execution data is already retained to make your code durable, so there’s nothing extra to capture or pay for. You can measure every run, not a sample.
The layer where your code is executed—agents, events, or async work—is also the layer that handles data from across your application, including product outcomes. Inngest is that layer. We let you score variants the same way you make code durable—adding primitives to existing code. Eval tools sitting outside the execution plan can correlate outcomes back to a variant manually, but it’s slow, brittle, and because of that often completely neglected. Inngest has the data attributed to the variant by default.
Yes. The same mechanism compares any two implementations—a vendor migration, a rewritten step, a new API call—on timing, error rate, and cost. AI evals are one use case, not the whole product.
You can depending on your use case, but it’s not necessary. You can drive variant selection from a flag you already use, and keep scoring tools where they help. Inngest adds the execution-level comparison those tools can’t see on their own.