
Large Language Models (LLMs) are fantastic artificial intelligence (AI) tools that help augment and support your day-to-day work, removing redundancy and a layer or two of tedium from many tasks.
If you’d like to dig straight into the code, it can be found here on GitHub.
One of the exciting areas of active development is autonomous agents, or AI, that can make decisions and perform actions on our behalf.
This fantastic idea can be partially created using OpenAI’s functional calling via the Chat completions application programming interface (API).
But, and this is a big but, you likely don’t want to trust the current state of the art in LLMs with making any decisions that might have even the slightest negative ramifications if it chooses wrong.
The reality is these LLMs hallucinate…
They make things up. They choose poorly. They are just plain wrong.
Not all the time, not every time, but frequently enough that you can’t just kick back and assume that the right choice will be made. This gets tricky, and the reason fully autonomous agents are something that is still well into the future.
Semi-Autonomous AI Agents
There’s a middle ground with semi-autonomous AI agents. We can leverage the tremendous power of LLMs to set us up and offer suggestions while still maintaining the power and control that we need to ensure they aren’t ordering 500 pizzas to our house or firing critical employees based on hallucinated “facts.”
This means we want to intercept the suggested actions, review them, and approve if they are executed.
This is challenging and something difficult to achieve in standard streaming chat UIs.
Where does the command interception happen?
How is the appropriate function invoked?
How do we stop mid-stream, ask for confirmation, and then pick up the workflow after an indefinite period has passed?
Imagine this conversation:
[human]: I’m hungry but don’t want to think about it too much. Can you order me some food?
[ai agent]: Sure, it’s Friday, and you usually order pizza. Should I order pepperoni and sausage?
[human]: presses the order button
It seems simple enough, as it should to the user, but the actual mechanics are complex. If you want to change the toppings or the food type, the complexity starts to skyrocket, and it can be an async coding nightmare. Your agent still needs to order the food… because LLMs don’t do that.
LLMs deal with words, not actions, so it’s still on you to program the workflow.
Programming the Workflow
To program the workflow, you need a handful of things in place: \
- A user interface (UI) to type into, receive responses, and confirm or deny the recommended actions that the agent recommends performing
- A system to capture the state of the workflow and manage each step of the asynchronous process
- A way to stream the responses back to the user as they occur
- A way to execute the actual work of the “agent.”
Seems simple on the surface, but the asynchronous aspect adds a lot of complexity. You can use the excellent @vercel/ai package that does much of the heavy lifting for building the chat-based UI. Still, it provides a relatively simple streaming response that doesn’t offer much guidance in intercepting messages and reacting to them with an agent, much less presenting the user with the power to make decisions to execute specific functions.
Let’s look at an example that combines Next.js, Inngest, PartyKit, Linear, and OpenAI wrapped up in a tidy monorepo with Turborepo to accomplish a semi-autonomous AI agent workflow.
In this example, you will see how you could use this stack to create a chat UI that reads from your Linear issues, returns relevant issues based on your question, and then allows you to perform actions on those issues!
Using Inngest to Manage the Asynchronous Workflow
Inngest shines here, providing a clear SDK for building complex async workflows within your Next.js applications, allowing you to execute long-running serverless processes using your existing hosting and infrastructure.
This is a big deal and is traditionally very tricky to pull off in a way that you can maintain long-term.
With Inngest? EZ
Yes, this is the Inngest blog, so obviously, we are biased, but stick with me here because this is cool. 😅
The first step is for the user to type a query in the chat UI. They can treat this like a standard ChatGPT conversation, or they can be more specific and ask the chat about issues in their Linear workspace.
import type { Message } from 'ai'import { customAlphabet } from 'nanoid';import { inngest } from '@/inngest/inngest.server.client';const nanoid = customAlphabet("0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz",7);export const runtime = 'edge'export async function POST(req: Request) {const body = await req.json()const { messages, requestId = nanoid(), confirm } = bodyif (confirm !== undefined) {// Confirm APIawait inngest.send({name: "api/chat.confirmed",data: {requestId,confirm,},});return new Response(requestId, { status: 200 });}console.log('start the chat')await inngest.send({name: "api/chat.started",data: {messages: messages as Message[],requestId,},});return new Response(requestId as string, { status: 200 });}
This POSTs a request to the /api/chat endpoint, dispatching an Inngest event that triggers the primary workflow.
export const aibot = inngest.createFunction({name: "OpenAI Linear Bot",cancelOn: [// Cancel this function if we receive a cancellation event with the same request ID can .// This prevents wasted execution and increased costs.{event: "api/chat.cancelled",if: "event.data.requestId == async.data.requestId",},],},{event: "api/chat.started"},async ({event, step}) => {const invoker = new FunctionInvoker({openai,functions,requestId: event.data.requestId,});const messages = await invoker.start(event.data.messages as AIMessage[], step);return messages;});
The workflow creates an instance of a FunctionInvoker class, which encapsulates most of the complexity of the overall process. The invoker takes several options, including the OpenAI API client, the function definitions, and a unique requestId that we will use to track where to send responses.
The OpenAI Chat completion functions are defined like this:
const functions: Functions = {search_issues: {docs: {name: "search_issues",description: "Search all issues for the given text",parameters: {type: "object",properties: {search: {type: "string",description: "The search term",},},required: ["search"],},},invoke: async (f: FunctionCall, _m: ChatCompletionRequestMessage[]) => {if (typeof f.arguments.search !== "string") {throw new Error("No search term provided");}return linear.issues({last: 5,filter: { searchableContent: { contains: f.arguments.search } },});},},delete_issue: {docs: {name: "delete_issue",description: "Delete an issue by ID",parameters: {type: "object",properties: {id: {type: "string",description: "ID of the issue to delete",},},required: ["id"],},},confirm: true,invoke: async (f: FunctionCall, _m: ChatCompletionRequestMessage[]) => {console.log("🤡 Not actually deleting issues!", f.arguments.id);return true;},},};
We are providing two functions to the Chat completion API. The first is for searching issues, and the second is for deleting an issue. Note that the deletion is stubbed in, so it doesn’t do anything in this example outside of logging to the server console.
The FunctionInvoker is genuinely complex and could use some additional refinement (PRs are welcome!), but it’s readable, and the complexity is contained and manageable.
But this introduces a problem. We are in the middle of an asynchronous workflow. We call the Open AI Chat API, which streams back a response.
How do we get the freaking responses back to the user? 🤔
Streaming Responses to the UI From an Asynchronous Workflow
The short answer is “web sockets,” but if you’ve ever dealt with web sockets, you might already be thinking about closing this tab and moving on with your day!
What if I told you that web sockets can be fun and straightforward?
“Don’t lie, Joel,” is a realistic and natural response!
It’s true, though, with PartyKit 🎈
PartyKit takes all the misery of dealing with web sockets and crushes them while providing a simple and effective mechanism for streaming responses to our users inside an asynchronous workflow.
/*** 🥳 Publish a message to the party. Sends a POST request to the partykit server.* The server then broadcasts it to all connected clients.** @param body* @param requestId*/export const publish = async (body: string, requestId: string) => {const partyUrl = `${process.env.NEXT_PUBLIC_PARTY_KIT_URL!}/party/${process.env.NEXT_PUBLIC_PARTYKIT_ROOM_NAME}`await fetch(partyUrl, {method: "POST",body: JSON.stringify({requestId,body,}),}).catch((e) => {console.error(e);})};
That’s it.
We call publish in our Function Invoker when we receive a response from OpenAI Chat completion API, which is forwarded to our PartyKit server via a POST message.
Inside the PartyKit server, we can broadcast that message to all connected clients.
async onRequest(_req: PartyRequest) {const messageBody: {requestId: string, body: string} = await _req.json();this.party.broadcast(messageBody.body);return new Response(`Party ${this.party.id} has received ${this.messages.length} messages`);}
Finally, in our handy React hook on the UI client side, we are listening for those messages to append them to the UI.
const socket = usePartySocket({room: process.env.NEXT_PUBLIC_PARTYKIT_ROOM_NAME!,host: process.env.NEXT_PUBLIC_PARTY_KIT_URL!,onMessage: (message) => {setLastMessage(message);}});
On the UI side, each message is parsed, and we can pick up when a function call that requires confirmation has been sent and present the user with a confirm/deny UI to progress the workflow.
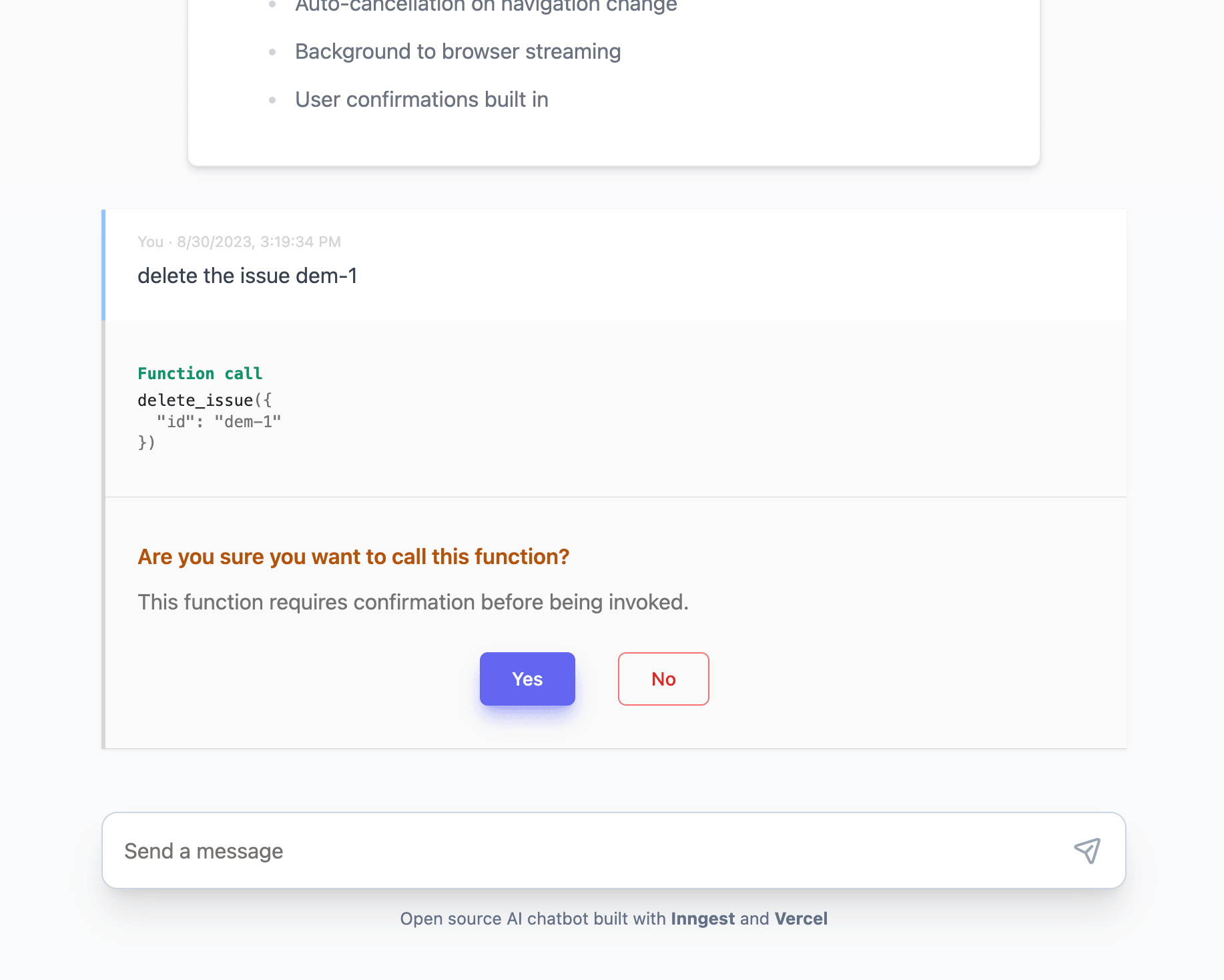
An interesting side effect of using PartyKit is that the workflow becomes multiplayer because you can connect to the process from multiple sessions. 🤯
This relatively simple example could be combined in so many exciting ways. The dream of asking ChatGPT to order your Friday night pizza could be a reality. All you need is a pizza-ordering API!
Try it Out!
The code for this semi-autonomous AI Agent workflow can be found on GitHub.
It only takes a few minutes to set it up if you’ve got your OpenAI and Linear API keys handy and follow these steps:
git clone https://github.com/joelhooks/inngest-partykit-nextjs-openaicd ingest-partykit-nextjs-openaipnpm icp /apps/web/.env.template /apps/web/.env.local- Edit
/apps/web/.env.localwith your OpenAI and Linear api keys pnpm dev- Visit http://localhost:3000
You can create a free Linear account, and they populate the project with a few issues that will work to test this out. If you feel adventurous, consider replacing Linear in this example with Github, allowing you to interact with your repositories in exciting ways.
It will be cool to see what you make with it, so please share!


