
If you've worked with hardware directly before, you understand the importance of making sure the inventory is accurate. Capacity planning, distribution of services and resources, repairs… all impossible without an accurate understanding of everything you own.
And that's the best case scenario. Worst case, you're looking at severe outages just because someone pulled the wrong cables, took the wrong disks, or powered off the wrong server.
As Inngest scales our own datacenter footprint, we needed to automate inventory sync across Ansible, libvirt, and NetBox without dividing or replicating coordination logic across each tool. In this post I'll show how we used Inngest to consolidate that logic into a single Go app.
An ETL problem
Since we started our journey off the cloud and into data centers, we've been using NetBox to help with inventory management for our hardware. It's a well known piece of software for people working with hardware devices and has pretty much all the things we need for now.
The main challenges were:
-
Ensure NetBox can serve as the source of truth. Meaning it needs to be up to date—data from various sources must be funneled into NetBox so we get a view of everything in one location. Those data sources include:
- Hardware information — models, quantity
- Ansible facts
- Interfaces
- Placement
There are others but these usually cover the most ground for us.
-
We built our own virtualization handling around
libvirt— more details on this for another day — which needs a source to reference for virtual machine placement. -
But before a virtual machine can be "placed", it needs to be scheduled, and we need something that can help with that coordination.
Here's what that looked like:
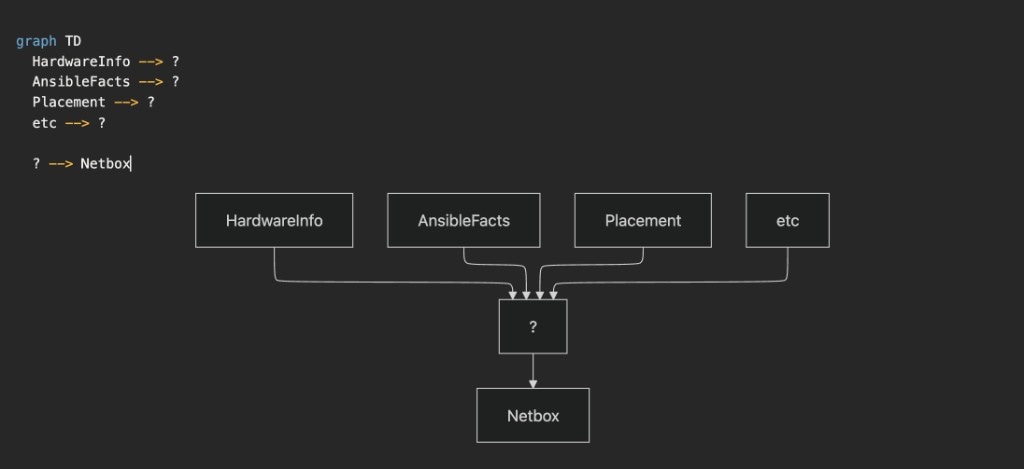
When drawn out like this, the shape looks a lot like an ETL. Which makes sense—we're really just taking data from one end, restructuring it, and then putting it at another location.
But it's that restructuring part that complicates things; this is where we need more logic and more conditions to ensure everything works together. On top of that, there's scheduling of resources, and clean up as well. That's a tall order for one solution.
Luckily, we have Inngest.
Architecture: Inngest as the coordination layer
Instead of each tool maintaining its own NetBox sync, tools now emit events describing what happened. An Inngest app receives those events and owns all the coordination logic: data transformation, NetBox writes, resource scheduling, error handling.
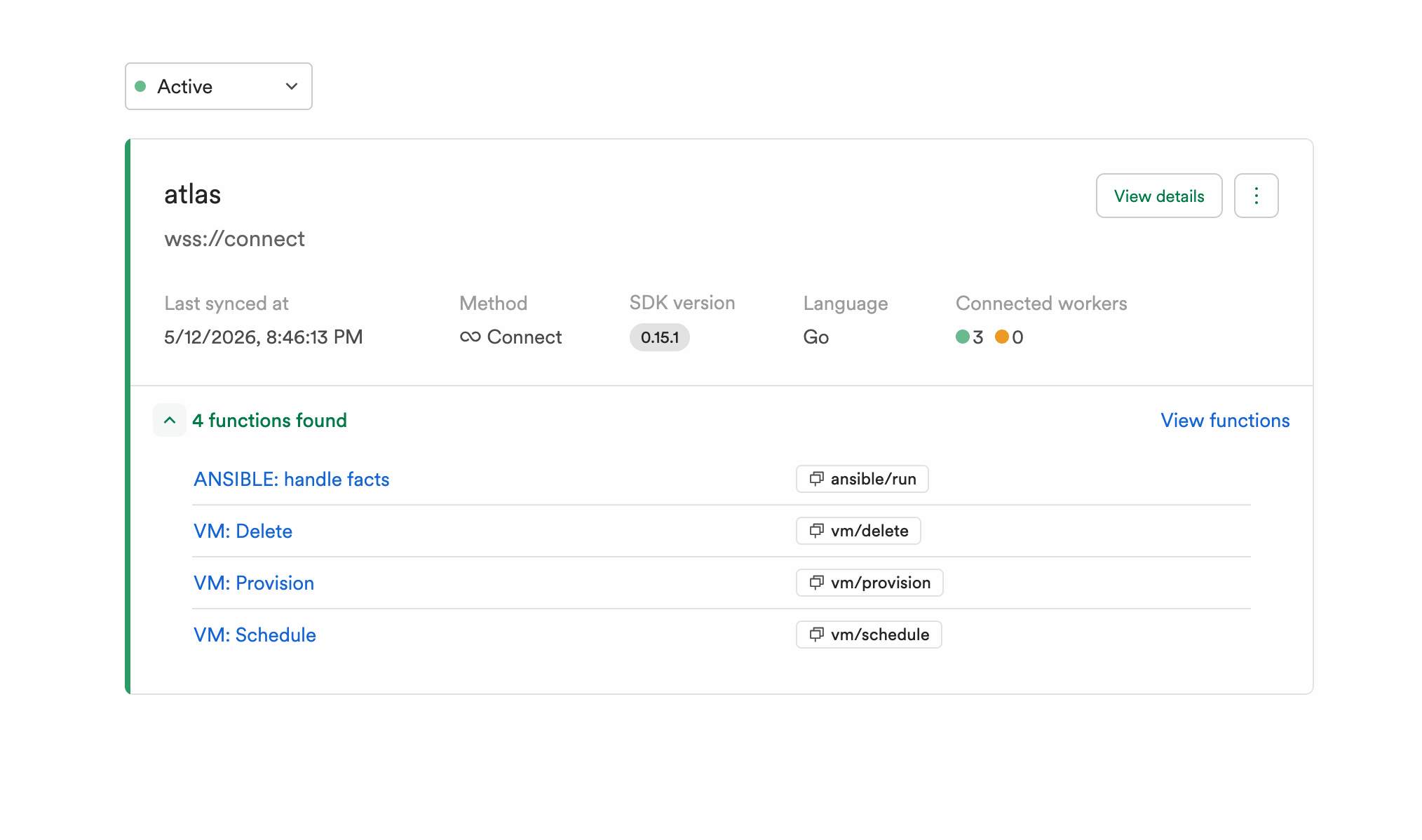
This workflow system is built with our Go SDK using the Connect method. The design is compact: 4 functions total, with 2 doing the primary work.
ANSIBLE: handle factsprocesses hardware and VM data collected by Ansible playbook runs and upserts the corresponding resources into NetBox.VM: Schedulehandles placement of virtual resources onto bare metal. Once placed in NetBox, the virtualization system (built aroundlibvirt) picks up the assignment and provisions accordingly.
On the Ansible side, a handler fires at the end of each playbook run. It collects host facts and sends them as an event to the Inngest event API:
# handlers/main.yml# webhook notification handler- name: Report to Inngest with factsansible.builtin.include_tasks: inngest.yml
# tasks/inngest.yml---- name: Refresh factsansible.builtin.setup:- name: Set Inngest report facts with out-of-band IPansible.builtin.set_fact:inngest_report_facts: "{{ ansible_facts | combine({'out_of_band_ip': out_of_band_ip}) }}"when:- out_of_band_ip is defined- out_of_band_ip | string | length > 0- name: Check if this is a molecule test instanceansible.builtin.set_fact:is_molecule_instance: "{{ (ansible_ec2_security_groups | default('') | lower is search('molecule')) or (lookup('env', 'MOLECULE_SCENARIO_NAME') | default('') != '') }}"- name: Send event to Inngestansible.builtin.uri:url: "{{ inngest_event_api }}"method: POSTbody_format: jsonbody:name: "ansible/run"data:inventory_hostname: "{{ inventory_hostname }}"facts: "{{ inngest_report_facts | default(ansible_facts) }}"headers:Content-Type: "application/json"status_code: [200, 201, 202, 204]when:- inngest_event_report- not is_molecule_instance | default(false) | boolchanged_when: falsefailed_when: false
Whether it's a bare metal server or a KVM guest, the handler collects findings at the end of the run and posts an ansible/run event. The failed_when: false is intentional. Inventory sync is not in the hot path. If the event API is unreachable, the playbook continues without crashing.
Here's a sample version of the code for handling bare metal data:
// handleBareMetal processes bare metal server facts and upserts to NetBoxfunc handleBareMetal(ctx context.Context, nbCl netbox.Client, data *AnsibleData, l logger.Logger) (any, error) {hostname, err := ansibleHost(data)if err != nil {return nil, inngestgo.NoRetryError(err)}// Extract ipv4/v6 from factsprimaryIPv4, err := findIPv4AddrFromFacts(data.Facts)if err != nil {l.Warn("no ipv4 address found")}primaryIPv6, err := findIPv6AddrFromFacts(data.Facts)if err != nil {return nil, fmt.Errorf("failed to extract IPv6 address: %w", err)}stepID := func(key string) string {return "bm: " + key}// retrieve site based on assigned ipv6 IP// NOTE sites are managed separately so there's no need to create onesite, err := step.Run(ctx, stepID("get site"), func(ctx context.Context) (*nb.Site, error) {// Find site by CIDR that contains the IPreturn nbCl.GetSiteByCIDR(ctx, primaryIPv6.IP)})if err != nil {return nil, fmt.Errorf("failed to retrieve site: %w", err)}// retrieve rack based on assigned ipv6 IP// NOTE racks are managed separately so there's no need to create onerack, err := step.Run(ctx, stepID("get rack"), func(ctx context.Context) (*nb.Rack, error) {ipv6, err := findIPv6AddrFromFacts(data.Facts)if err != nil {return nil, fmt.Errorf("failed to extract IPv6 address: %w", err)}return nbCl.GetRackByCIDR(ctx, ipv6.IP)})if err != nil {return nil, fmt.Errorf("failed to retrieve rack for device: %w", err)}// manufacturermfr, err := step.Run(ctx, stepID("get or create manufacturer"), func(ctx context.Context) (*nb.Manufacturer, error) {fields := bareMetalManufacturerFields(data.Facts)return nbCl.GetOrCreateManufacturer(ctx, fields.name, fields.slug)})if err != nil {return nil, fmt.Errorf("failed to retrieve manufacturer: %w", err)}// device typedeviceType, err := step.Run(ctx, stepID("get or create device type"), func(ctx context.Context) (*nb.DeviceType, error) {fields := bareMetalDeviceTypeFields(data.Facts)return nbCl.GetOrCreateDeviceType(ctx, *mfr.Id, fields.name, fields.slug)})if err != nil {return nil, fmt.Errorf("failed to retrieve device type: %w", err)}// device role// NOTE roles are managed separately so no need to create onerole, err := step.Run(ctx, stepID("get device role"), func(ctx context.Context) (*nb.DeviceRole, error) {return nbCl.GetDeviceRole(ctx, "baremetal")})if err != nil {return nil, fmt.Errorf("failed to retrieve device role: %w", err)}platform, err := step.Run(ctx, stepID("get platform"), func(ctx context.Context) (*nb.Platform, error) {return nbCl.GetPlatform(ctx, bareMetalPlatformSlug(data.Facts))})if err != nil {return nil, fmt.Errorf("failed to retrieve device platform: %w", err)}// Upsert devicedevice, err := step.Run(ctx, stepID("upsert device"), func(ctx context.Context) (*nb.DeviceWithConfigContext, error) {return nbCl.UpsertDevice(ctx, hostname, netbox.UpsertDeviceOpt{SiteID: *site.Id,DeviceTypeID: *deviceType.Id,DeviceRoleID: *role.Id,RackID: rack.Id,Platform: platform,SystemResources: bareMetalDeviceSystemResources(hostname, data.Facts),})})if err != nil {return nil, fmt.Errorf("failed to upsert device: %w", err)}// Map disks to module bays so NetBox captures physical inventory._, err = step.Run(ctx, stepID("sync disk module bays"), func(ctx context.Context) (any, error) {disks, err := findDiskDevicesFromFacts(data.Facts)if err != nil {if errors.Is(err, ErrNoDiskDevices) {l.Warn("no disk devices found")return []*nb.ModuleBay{}, nil}return nil, err}return syncDiskInventory(ctx, nbCl, device, disks, l), nil})if err != nil {return nil, fmt.Errorf("failed to sync disk module bays: %w", err)}// Sync interfaces and IP addresses// Get list of interface namesinterfaceNames, ok := data.Facts["interfaces"].([]any)if ok {// Process each interfacefor _, ifaceNameRaw := range interfaceNames {ifaceName, ok := ifaceNameRaw.(string)if !ok {continue}// Skip// - loopback and ephemeral veth interfaces// - virtual ethernet pairs (ephemeral container interfaces)if ifaceName == "lo" || strings.HasPrefix(ifaceName, "veth-") {continue}// Wrap each interface sync in its own stepiface, err := step.Run(ctx, stepID(fmt.Sprintf("sync interface %s", ifaceName)), func(ctx context.Context) (*ifaceSyncResult, error) {ansibleIface, err := parseInterface(ctx, ifaceName, data.Facts)if err != nil {l.Error("error parsing interface", "error", err)return nil, err}return syncInterface(ctx, nbCl, device, ifaceName, ansibleIface, l)})if err != nil {l.Warn("failed to sync interface", "interface", ifaceName, "error", err)continue}if shouldAllocateStaticIPv6(ifaceName, iface) {res, err := step.Run(ctx, stepID(fmt.Sprintf("allocate ipv6 %s", ifaceName)), func(ctx context.Context) (*ipv6AllocationResult, error) {return allocateStaticIPv6(ctx, nbCl, device, rack, ifaceName, l)})if err != nil {l.Warn("error allocating ipv6 address for interface", "interface", iface.Name, "error", err)// Don't fail the whole operation if IPv6 allocation fails}if allocated := primaryIPv6FromAllocation(res, l); allocated != nil {primaryIPv6 = allocatedl.Info("set allocated IPv6 as primary", "address", res.Address, "interface", ifaceName)}}}} else {l.Warn("interfaces field not found or invalid")}if oobIP := stringFact(data.Facts, "out_of_band_ip"); oobIP != "" {_, err = step.Run(ctx, stepID("sync out-of-band interface"), func(ctx context.Context) (*ifaceSyncResult, error) {return syncOutOfBandInterface(ctx, nbCl, device, oobIP, l)})if err != nil {l.Warn("failed to sync out-of-band interface", "address", oobIP, "error", err)}}// Update device primary IPs if we found default addressesif primaryIPv4 != nil || primaryIPv6 != nil {_, err = step.Run(ctx, stepID("update primary IPs"), func(ctx context.Context) (any, error) {return updatePrimaryIPs(ctx, nbCl, device, primaryIPv4, primaryIPv6, l)})if err != nil {l.Warn("failed to update device primary IPs", "error", err)// Don't fail the whole operation if primary IP update fails}}return map[string]any{"status": "success","device_id": *device.Id,"device_name": *device.Name,"type": "bare metal",}, nil}
Each step.Run call is checkpointed. If NetBox crashes mid-function (which happens), only the failed step retries, while completed steps don't re-execute. The default 4 retry attempts handle most transient failures without additional error-handling code.
What retries and reruns solve for operations
Two specific Inngest capabilities matter here more than the rest.
- Retries against transient NetBox failures.
NetBox by nature is a Django app. Generally speaking, it's not the most efficient thing in the world—sorry if I offended any Django lovers out there. We run it in Kubernetes and haven't invested heavily in making it highly available. It crashes occasionally, even under light load. Kubernetes restarts it, but requests that hit the window between crash and restart fail. The default retry policy absorbs those failures automatically.
Inngest retries make the workflow a lot smoother by backing off when it fails, and the default attempt of 4 usually will get things through. Instead of spending more time trying to make an internal app more reliable, we can now cruise through transient issues that are low priority for us to deal with.
- Reruns after deploying fixes.
When we introduced a bug in the inventory upsert logic, the Inngest UI showed which runs failed and why. After deploying the fix, we reran the failed runs from the dashboard. They reprocessed to completion using the original event payloads. No need to trigger fresh Ansible runs or manually reconcile state.
Both of these reduce the operational burden of maintaining an internal tool that doesn't justify heavy investment in reliability engineering.
Operational results
Hardware inventory automation improved significantly after this implementation. Most hardware data now populates automatically from Ansible Facts during Ansible playbook runs including hardware provisioning. Some caveats remain: rack position isn't available from the kernel, so physical rack mount placement still requires manual entry.
VM lifecycles are more accurate and easier to manage across the different tools responsible for scheduling, provisioning, and decommissioning. Each tool owns its piece, emits events describing what it did, and the Inngest app maintains the coordinated view in NetBox.
The architecture extends to new datacenter locations without modification. Each location emits the same event schemas. NetBox tracks site relationships. No new coordination logic required.
What's next
This inventory automation covers our immediate needs. But the architecture we're deploying here supports more. Because every operational action already flows through as an event, adding new workflows is additive rather than requiring new infrastructure.
A few directions we're thinking of:
Datacenter expansion. The architecture works across locations without modification. Each new site emits the same event schemas (ansible/run, vm/schedule). NetBox tracks site relationships and regional hardware configuration differences. No new coordination logic or infrastructure required per site.
Asset lifecycle tracking. The current system covers provisioning and ongoing state sync. The natural extension is covering the full hardware lifecycle: procurement delivery, installation confirmation, scheduled maintenance windows, decommissioning. Each stage emits events, Inngest coordinates the state transitions in NetBox. Business teams can query current asset status and generate utilization reports directly.
Cost tracking. Hardware purchase costs flow through procurement events. The Inngest app can aggregate total cost of ownership per device by linking purchase, warranty, and maintenance costs to inventory records. Warranty expiration events trigger automated alerts for renewal planning.
Capacity planning. The placement events already carry resource allocation data. Aggregating that into running totals of available capacity per rack and per site is straightforward. Historical placement trends provide forecasting inputs. Automated procurement workflows can trigger when capacity thresholds are reached.
Integration expansion. Other operational tools connect to the same event infrastructure. Monitoring systems emit health events on hardware issues. Ticketing systems receive inventory alerts. IPAM tools coordinate IP address management. Certificate management triggers rotation workflows before expiration. Each integration is additive. The event schema is the contract, not direct service-to-service coupling.
Why this pattern matters for operations teams
Infrastructure automation commonly scatters logic and data across various tools/teams. Each team owns their piece of the infrastructure puzzle. Coordination happens through shared databases or direct service calls between tools. This tight coupling slows down development, and increases operational complexity because debugging problems requires understanding how all the pieces interact.
Event-driven architecture decouples these systems. Tools emit events describing what happened without knowing who processes them. The coordination layer determines the response to each event type. Business logic consolidates in one maintainable codebase instead of spreading across team boundaries. Teams move independently because they depend on event schemas, not implementation details.
For infrastructure automation at scale, this architectural pattern works well. We get centralized coordination of distributed systems. Execution happens where it makes sense rather than being constrained by architectural decisions. There's clear separation of concerns between tools and coordination logic.


