
Everyone's asking "WTF is a loop?" Here's the question nobody's asking: what runs the loop?
The AI discourse has converged on loops as a core primitive of agentic systems. Matt Van Horn traced the lineage of agent loops from ReAct to tool-use to orchestration loops to loops supervising loops. Addy Osmani broke down the building blocks inside loops: automations, worktrees, skills, connectors, sub-agents. Van Horn landed on durability, arguing that loops which can't survive a restart aren't loops. Osmani's key thread was orchestration: design the system that prompts the agent instead of you.
I want to take their points further. Durability isn't just a property of the loop. It's the entire execution layer underneath it. The important fact is that durable orchestration is fundamental to building your agent loop architecture. Let's break down that architecture.
Where loops break
The /loop and /goal patterns handle single-agent, single-session work well. An agent loops until a task is done. That covers a lot of ground. But the next stage (Stage 5 in Van Horn's framing) is where it falls apart:
- Loops supervising other loops
- Loops running on schedules, not just triggered by a human
- Loops that survive process restarts, deploys, and crashes
- Loops that spawn sub-agents and wait for results (sometimes hours later)
- Loops that need to be observable after the fact
That's not a prompting problem. That's an infrastructure problem.
Van Horn cites @runes_leo: "The costliest thing in AI coding is no longer writing code, it's managing the agent loop." A while True in a terminal doesn't give you any of this. Neither does a long-running process on a VM or sandbox.
Think about what happens when you run an agent loop on a server. The process will die or restart. A deploy, an OOM, a spot instance reclamation. The loop restarts. But what was it doing? Which step was it on? Did it already send that Slack message? Did it already invoke the sub-agent?
You don't know. It starts over. Re-fetches data it already had. Re-calls the LLM for decisions it already made. Sends a duplicate notification. Spawns a duplicate sub-agent. You wake up to three identical Slack messages and a confused team.
The fix isn't "better error handling" — it's an execution model where each step is checkpointed, each decision is persisted, and recovery means resuming from the last successful step.
The agent loop architecture in three layers
Three layers. Each one maps to a concrete primitive.
Layer 1: The Loop
A loop is a cron plus a decision-maker. It runs on a schedule (or a trigger), evaluates state, and decides what to do next.
This is Van Horn's definition made concrete: what cron never had is the decision in the middle. The agent decides, not you. The cron is the heartbeat. The LLM is the decision-maker. Steps are the durable execution that checkpoint progress.
export const infraHealthCheck = inngest.createFunction({ id: "infra-health-check" },{ cron: "*/30 * * * *" }, // Every 30 minutesasync ({ step }) => {const metrics = await step.run("fetch-service-metrics", async () => {return await fetchServiceMetrics(); // error rates, latency, memory, CPU});const assessment = await step.run("assess-health", async () => {return await callLLM({prompt: `Given these service metrics, classify overall system healthas "normal", "degraded", or "critical". Explain your reasoning.Metrics: ${JSON.stringify(metrics)}`,});});if (assessment.status === "degraded" || assessment.status === "critical") {await step.invoke("triage-incident", {function: incidentTriage,data: { metrics, assessment, services: assessment.affectedServices },});}});
Every 30 minutes, the loop fires. It fetches data, asks the LLM whether the system is healthy, and invokes a skill if not. If the process restarts between steps, the already-completed steps don't re-execute. That's the loop. Not the LLM, the loop around the LLM.
Layer 2: The Skill
In this context, a skill is not a prompt. It's a durable workflow. Multi-step, retryable, composable, independently deployable.
Van Horn: "The loop is plumbing. The asset is the skill it calls." This is the part that compounds. Each new skill the system learns makes every loop more capable.
export const incidentTriage = inngest.createFunction({ id: "incident-triage", retries: 3 },{ event: "infra.incident.triage" },async ({ event, step }) => {const details = await step.run("fetch-detailed-metrics", async () => {return await fetchDetailedMetrics({ services: event.data.services });});const deploys = await step.run("fetch-deploy-history", async () => {return await fetchRecentDeploys({ since: hoursAgo(2) });});const analysis = await step.run("correlate-incident", async () => {return await callLLM({prompt: `Correlate these service metrics with recent deploys.Identify the likely root cause and severity.Metrics: ${JSON.stringify(details)}Recent deploys: ${JSON.stringify(deploys)}`,});});await step.run("post-triage-summary", async () => {await slack.postMessage({channel: "#incidents",text: formatTriageSummary({analysis,affectedServices: event.data.services,recommendedActions: analysis.recommendations,}),});});return analysis;});
This skill fetches, classifies, and routes. It's a unit of work with built-in fault tolerance. The skill can be an AI workflow with an LLM in the middle or deterministic code.
Layer 3: The Orchestrator
The orchestrator is the engine that runs everything: schedules crons, executes steps, manages retries, enforces concurrency limits, stores run history, and hot-deploys new functions/workflows without disrupting running ones.
This is the layer nobody talks about because it's supposed to be invisible. But it's foundational.
Most people think about agents as "LLM + tools." The agent loop architecture re-frames this as agents being "loops + skills + orchestration." The LLM + tools are inside the loops. LLMs and tools can be swapped or tweaked while the architecture remains. The orchestration enables the architecture.
What happens when things break
The happy path is easy. But this is software running in production — do things ever really go according to plan?
Your incident triage skill fires and the metrics API times out. The read had to go to disk and the in-memory cache didn't have the data. The step calling this API now retries and hits the API again. The data is now partially cached and the API completes. The skill continues with the next step like nothing ever happened.
Sometimes, it may not be as simple as that. What if an API key expires, or your hosting provider is down for 30 minutes? All of your retries are exhausted. Now what happens? You have to also handle failures.
export const incidentTriage = inngest.createFunction({id: "incident-triage",retries: 3,onFailure: async ({ error, event, step }) => {// The function failed after exhausting retries.// We still have the original event data. Nothing is lost.await step.run("notify-failure", async () => {await slack.postMessage({channel: "#agent-ops",text: `⚠️ Incident triage failed: ${error.message}. ` +`Will retry on next health check cycle. ` +`Affected services: ${event.data.services.join(", ")}`,});});},},{ event: "infra.incident.triage" },async ({ event, step }) => {/* the same logic as the skill above */});
The onFailure handler fires after all retries are exhausted. It posts to an ops channel so someone knows. The event is preserved, nothing is lost. The next scheduled run picks up where the failed one couldn't.
Durable orchestration must give you step-level retries for transient errors and failure handling hooks for non-recoverable errors. Without this, things break (as they do), and you find out hours or days later.
Transient errors are also expensive. If your skill or agent retries from the beginning, you're calling LLMs multiple times and burning tokens unnecessarily. The LLM call can be checkpointed. Now multiply this by 10, or 30, agents across your system. That's expensive.
Step-level checkpointing isn't just a correctness feature. It's a money saver.
The agent that builds its own skills
This is where it gets more interesting. The system is not static — it is designed to evolve and extend itself.
The agent doesn't just run inside loops — it authors new loops and registers them with the orchestration engine. Each deployed function is a durable skill that runs independently, triggerable from a loop or agent or running on a schedule, with its own retry logic. Skills compound.
It's an orchestration-aware agent.
Here's how it works. An AI agent has access to the orchestration SDK as a tool. It can write new functions, register them with the engine, and they start running immediately. The agent process hot-reloads new functions without restarting or disrupting in-flight runs.
Walk through a concrete example:
1. A human expresses a need. Engineer says: "Our services keep having latency spikes overnight and nobody notices until morning." This is the trigger. The agent doesn't need to infer a vague pattern from ambient data. It has clear instructions.
2. Agent writes a skill. Two multi-step functions: a health check loop that runs every 30 minutes, pulling error rates, latency, and resource usage, with the LLM classifying system health as normal, degraded, or critical. And an incident triage skill that fetches detailed metrics and recent deploy history, correlates root causes with an LLM, and posts a triage summary to Slack with recommended actions. Error handling: if the metrics API is down, back off and retry. If the LLM fails, fall back to rule-based severity classification.
3. Agent deploys the skill. The agent writes the function code that's picked up by a sidecar process. The new functions are registered automatically. They're live immediately, with no deploy pipeline, no PR.
4. Skill runs autonomously. Every 30 minutes, the engine triggers the health check. If something's wrong, it invokes the triage skill. No human in the loop. Fully durable.
5. Agent iterates on signal. This is the part people gloss over, so let me be specific about what "iterates" means. The agent doesn't magically notice patterns. It has a separate review loop: a cron-triggered function that runs weekly, reads the run history from the orchestrator, and evaluates performance:
export const reviewSkillPerformance = inngest.createFunction({ id: "review-skill-performance" },{ cron: "0 10 * * 5" }, // Every Friday at 10amasync ({ step }) => {const runs = await step.run("fetch-run-history", async () => {return await getInngestRuns({functionId: "incident-triage",since: daysAgo(7),});});const analysis = await step.run("analyze-performance", async () => {const successRate = runs.filter(r => r.status === "completed").length / runs.length;const avgDuration = average(runs.map(r => r.duration));const incidents = await fetchIncidentOutcomes(); // Did incidents correlate with actual outages?return await callLLM({prompt: `Review this skill's performance over the past week.Success rate: ${successRate}Avg duration: ${avgDuration}msIncidents correlated with real outages: ${incidents.confirmed}/${incidents.total}False positives: ${incidents.falsePositives}Team acted on alerts: ${incidents.actedOn}/${incidents.total}Should we adjust thresholds or classification? What specific changes?`,});});if (analysis.shouldModify) {await step.invoke("update-skill", {function: coreAgent,data: { prompt: `Update the incident-triage skill based on the following proposed changes: ${analysis.proposedChanges}` },});}});
The "review" is a function. It reads run history, checks whether incidents correlated with actual outages, and feeds that signal to the LLM. If the health check keeps flagging a service as degraded but the team ignores it because the thresholds are too sensitive, the review loop catches it, and the skill gets updated to adjust the classification. Not magic. A cron job with an LLM in the decision seat.
What about validation? The agent writing code is only as good as the guardrails around it. The code can be type checked. The agent can invoke the function itself to test it, as it's able to interact with the orchestration engine directly. While it's not bulletproof, you are giving the core agent the ability to debug the skills it writes natively within the system it operates. The review loop catches issues that aren't caught with the initial debugging.
Taking this a degree further, the agent can use onFailure hooks to trigger itself to evaluate a given failure. It's a feedback loop that keeps improving.
What about conflicts? Flow controls — specifically, concurrency controls or singletons — handle the simple case (concurrency: [{ limit: 1, key: "event.data.service" }]), meaning only one incident triage runs at a time per service. But the deeper question is: what if two health checks both detect issues in the same service simultaneously? The orchestrator queues them. The second triage waits until the first completes. No duplicate alerts, no race conditions. This isn't theoretical. It's the same concurrency primitive you'd use in any job queue.
The agent isn't just executing tasks. It's building infrastructure for itself. Each skill persists beyond the conversation that created it. Kill the agent process and restart it. The skills keep running. Swap the underlying model. The skills keep running. The agent is ephemeral — its output is durable.
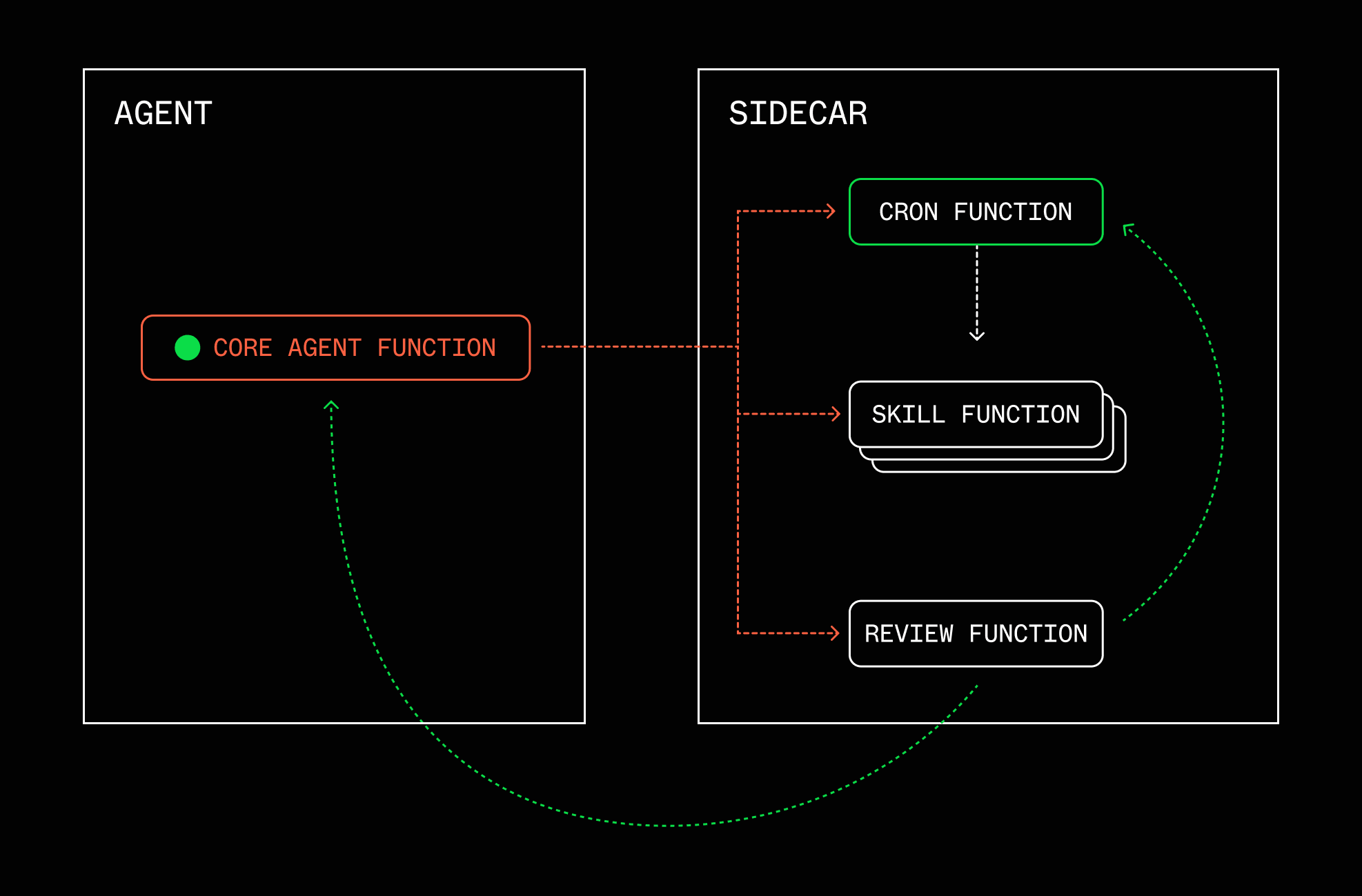
The developer's view
This matters because if the developer can't see what the agent deployed, debug what broke, and audit what ran at 3am, the whole architecture is a major liability.
The orchestration engine stores every run, every step, every input, every output, every retry. A skill the agent deployed last Tuesday that failed at 4am? You can see exactly which step failed, what the input was, what error it threw, and how many times it retried before giving up. Full traces down to the step level are the output of the orchestration engine itself.
This isn't a dashboard bolted on after the fact. It's inherent to durable execution. Every step.run() is a checkpoint. Every checkpoint is observable. When the thing that wrote the code isn't a human, observability isn't a nice-to-have — it's the trust layer.
Day-to-day, the developer's workflow looks like this: check the runs dashboard in the morning. See which skills ran overnight, which succeeded, which failed. If a skill the agent wrote is misbehaving, you can read the code directly, edit it, delete it, or tell the agent to fix it. The agent authored it, but you own it. The agent and its skills are still a garden that you should tend to.
Why durability is foundational
Van Horn: "These things have to survive a restart."
Here's what durability means in practice:
| Requirement | What it means | Why a basic while loop fails |
|---|---|---|
| Independent step retry | If step 3 of 5 fails, retry step 3, not steps 1 and 2 | A loop restart re-runs everything from scratch |
| Sub-agent lifecycle | Spawn a child task, wait for it (maybe hours), cancel if the parent is cancelled | No built-in parent-child lifecycle management |
| Guaranteed event delivery | If an event fires while the agent is down, it should still be processed | Events are lost if the process isn't running |
| Post-hoc observability | See what happened after the fact: every step, every decision, every retry | Logs are your only option, and they're ephemeral |
| Hot-deploy without downtime | Deploy a new function version without killing in-flight runs | Process restart kills everything |
| Concurrency control | Only run N instances of a skill at a time | No built-in concurrency primitives |
"Just run it in a container" gets you uptime. It doesn't get you correctness. A container that restarts after a crash brings the process back, but every in-flight loop starts over. Every step re-executes. Every LLM call is re-made. The loop looks like it's running, but it's running blind.
How this compares to existing tools
Some tools may offer you a "pretty" turnkey solution to this type of system, or you might choose to cobble together some lower-level tools and create your own system. Neither choice is wrong, but the right architecture layer should allow you — and your agent — to evolve over time. Flexible, dynamic, durable.
What you want: durable execution primitives that fit an agent well, that an agent can easily write, plus the observability and APIs that let the agent itself be orchestration-aware.
A working example
We're testing these patterns internally at Inngest, and you can see a concept of this in the "utah" project repo here: github.com/inngest/utah. It's an agent harness built on top of Inngest's durable orchestration that is also orchestration-aware.
The system has a sidecar process that enables the main agent to write and edit Inngest functions in its own workspace, extending itself with "skills" (in the context of this article). Soon, we're planning to provide an entire system with starter loops as examples, but the ideas there can demonstrate the ideas in this article a bit more clearly.
The compounding loop
Satya Nadella's recent post named something the industry has been feeling: the moat isn't the model — it's the loop.
His framing: there are two types of capital. Human capital, the knowledge and judgment your team built over years. And what he calls token capital, the AI workflows, decision patterns, and learned skills a company builds on top of foundation models.
The thesis: these compound together. Every improved workflow generates better signal. Better signal produces sharper AI behavior. Sharper behavior frees up human attention for higher-judgment work. A hill-climbing machine.
This is what the agent loop architecture enables concretely:
- Every durable skill the agent deploys is institutional knowledge encoded as executable infrastructure. It persists. It runs whether or not a human is watching.
- A cron-triggered review loop that evaluates skill performance and iterates. That's the hill-climbing machine made real. Not a flywheel diagram in a deck. A function with a cron trigger.
- If your skills die on process restart, the compounding resets to zero. Durability is what makes the investment persist.
Nadella's key point: "A company should be able to switch out a 'generalist' model without losing the 'company veteran' expertise built into their learning system." That's the skill library pattern. Durable functions don't care which LLM calls them.
Build accordingly
The conversation has been about what agents do: loops, tools, reasoning, context engineering. The next conversation is about what runs the agents.
Three layers: loop, skill, orchestrator. The loop is the unit of work. The skill is the asset. The orchestration engine is what makes both durable. The sidecar pattern is the model: an agent writes its own durable skills, deploys them, reviews how they perform, and iterates. Not a thought experiment. It's a working model.
We built Inngest to be the orchestration engine for this: step.run(), step.invoke(), cron triggers, event-driven control flow, concurrency controls, and full step-level observability. But the architecture pattern is bigger than any single tool. If you're building agent loops in production, define the three layers.
The primitives exist today. Build accordingly.


